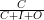 rappel =
rappel = 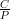
C’est après la seconde guerre mondiale et plus précisément avec l’accroissement des tensions Est-Ouest que les systèmes d’extraction automatique d’information ont fait leur apparition. Les militaires désiraient en effet collecter un maximum d’informations géopolitiques dans les documents publics ou secrets qu’ils avaient à leur disposition, mais dont la masse ne permettait pas une lecture humaine complète. La fin de la guerre froide puis la chute du bloc communiste a mis fin à cette mainmise militaire sur le domaine de l’extraction d’information, avec l’organisation, dès 1987, de la conférence MUC (Message Understanding Conference).
Cette conférence, dont le thème est la compréhension automatique de textes et l’extraction de leur information, a progressivement créé un consensus sur la définition de ces domaines [Appelt, 1999]. Elle a formellement défini la notion d’extraction d’information et sert actuellement de référence dans cette matière. Les publications qui lui sont attachées constituent l’état de la recherche du domaine. Elle est organisée selon le principe de la compétition entre les systèmes participants qui doivent donc se plier à ses critères de travail et d’évaluation [Chinchor, 1992]. Notamment, il s’agit de présenter un système dont le résultat soit une structure hiérarchique d’attributs-valeurs couramment appelée formulaire (template) et d’accepter l’évaluation et la publication des résultats dudit système. Cette évaluation s’effectue sur la base de corpus de taille moyenne pour obtenir les formulaires de référence à l’idéal. Ces textes sont au nombre de 1 300, contenant environ 400 000 mots pour un vocabulaire de 18 000 mots. Les textes contiennent 12 phrases composées en moyenne de 27 mots [Chinchor et al., 1994].
Est considéré comme correct (C) un formulaire extrait dont la valeur est
conforme à celle du formulaire de référence correspondant. Si cette valeur ne
correspond pas, le formulaire est incorrect (I). Dans le cas où un attribut est
présent dans le formulaire extrait mais qu’il est différent de l’attribut du
formulaire de référence correspondant, il y a surgénération (O). À l’aide de ces
résultats, il est possible de déterminer la précision (P) et le rappel (recall) (R)
du système :
précision =
rappel =
On appelle F-mesure (F-measure) un résultat statistique qui découle de la
combinaison de la précision et du rappel, pondéré par un paramètre β dont la
variation à partir de 1.0 détermine si le rappel ou la précision est de plus de
poids :
F = 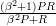
La précision, le rappel et la F-mesure sont les mesures les plus fréquentes qui permettent d’évaluer les capacités d’un système d’extraction d’information. La précision indique la proportion des réponses correctes dans l’ensemble des réponses apportées par le système. Le rappel évalue le rapport entre le nombre de réponses correctes apportées par le système et l’ensemble des réponses correctes présentes dans la base interrogée [Salton et McFill, 1983]. La F-mesure est une mesure qui calcule l’harmonisation pondérée entre la précision et le rappel pour l’évaluation des systèmes. La pondération est habituellement de β=1.0 pour harmoniser l’importance conférée à la précision et au rappel [Makhoul et al., 1999], mais il est parfois utile de montrer le comportement des applications en privilégiant également la précision (β=0.5) et le rappel (β=2.0) [Lewis, 1992].
Par ailleurs, la conférence MUC a défini deux modes d’évaluation des systèmes qui lui sont soumis. L’un de ces modes met l’accent sur la précision et détermine la perfection du système par des résultats de 100% de rappel pour 100% de précision. Le second mode privilégie la pureté des réponses et établit l’excellence par des résultats de 100% de rappel pour 0% de surgénération.
Des diverses applications présentées pour concourir, les conférences MUC successives ont dégagé différentes tâches générales vers lesquelles ces systèmes tendaient. En fonction de leur objectif – la plupart de ces systèmes ne traitent pas l’intégralité des tâches recensées par MUC –, les systèmes sont évalués en fonction de leur capacité à résoudre ces tâches :
Suite au succès rencontré par MUC, d’autres conférences ont rapidement vu le jour, qui abordent des sujets semblables ou connexes. Notamment, depuis sa première édition en 1992, la compétition TREC a pris une place prépondérante dans le domaine de la gestion de l’information textuelle 1 [Harman, 1992]. Moins ambitieuse que MUC, TREC a pour objectif non pas la compréhension de textes, mais l’identification dans des documents d’éléments informationnels qui composent une information recherchée, préalablement définie ou non. Cette définition d’un objectif moins strict que celui de MUC permet d’envisager plusieurs facettes du problème.
Ces différentes perspectives s’actualisent autour de plusieurs tâches, présentes dès l’origine de la conférence ou qui ont vu le jour au cours des différentes éditions.
Les systèmes que nous décrivons dans ce chapitre viennent à la suite de l’initiative MUC. Ils possèdent en commun une approche automatisée de l’apprentissage de structures textuelles, sémantiques ou non, qui leur permettent d’identifier l’information pertinente dans les textes, et donc de constituer une structure sémantique plus ou moins complète des textes utilisés. À ce titre, ils constituent un aperçu des méthodes de construction automatique d’un dictionnaire sémantique local en extraction d’information. De ce fait, leur domaine d’application est généralement spécialisé. Notre démarche, bien que visant une compréhension plus globale des textes, s’appuie sur certains processus similaires à ceux que ces systèmes mettent en œuvre.
Il existe trois classes de systèmes d’extraction d’information, selon le type de texte que le système est capable de gérer, même si certaines approches peuvent être polyvalentes [Soderland, 1999]. Le texte libre correspond au langage écrit selon les règles grammaticales en vigueur dans la langue utilisée mais sans autre contrainte. Un article de journal ou le texte d’un roman est généralement libre, comme le texte d’une encyclopédie :
« Le génie de Victor Hugo est partout, dans tous les genres littéraires qu’il bouleverse et s’approprie – du roman au drame, de la poésie à la critique, de l’ode au pamphlet – comme dans cette facilité à se faire l’acteur des grands rôles publics. » 2
Le texte structuré répond à des règles très strictes et l’information dont il est porteur est régulière dans sa nature, sa présence, sa position. L’information cataloguée (date, œuvre, genre) de ce tableau
| 1829 | Marion Delorme | Drame |
| 1830 | Hernani | Drame |
| 1831 | Notre-Dame de Paris | Roman |
correspond au texte suivant 3, dont la structure est concrétisée par des balises :
<tr class="cell2" valign="top">
<td align="center"> 1829 </td> <td align="left"> Marion Delorme </td> <td align="left"> Drame </td> </tr> |
<tr class="cell1" valign="top">
<td align="center"> 1830 </td> <td align="left"> Hernani </td> <td align="left"> Drame </td> </tr> <tr class="cell2" valign="top"> <td align="center"> 1831 </td> <td align="left"> Notre-Dame de Paris </td> <td align="left"> Roman </td> </tr> |
Enfin, le texte semi-structuré suit rarement la grammaire de la langue et se présente sous un style plus ou moins télégraphique, sans règle rigide ni sans forme prédéfinie. Il est en général porteur d’une information utilitaire.
Le texte que nous devons traiter dans le cadre de cette recherche est à l’intersection du texte libre, puisque le contenu est en général grammatical et que l’information qu’il contient est imprévisible, et du texte semi-structuré, étant donné qu’il s’agit d’un dictionnaire encyclopédique qui répond à des règles de présentation dans l’intitulé de ses articles et qu’une structure XML sous-jacente en identifie certains éléments.
La normalisation des résultats de l’extraction d’information au sein de la conférence MUC demande une structure attribut-valeur appelée formulaire dans le cadre de la conférence. En réalité, le sens de ce vocable varie selon les approches, et cette structure porte tantôt le nom de « signature » [Riloff et Lorenzen, 1999], tantôt celui de « cadre » (frame) [Soderland, 1999] ou de « patron » (pattern) [Kim et Moldovan, 1993]. Il reste toutefois que cette structure, quel que soit le nom que l’on lui donne, contient toujours au moins un « emplacement » ou une « case » (slot) destiné à recevoir un élément d’information d’une catégorie sémantique déterminée.
Or là où certains systèmes peuvent mettre en rapport, au sein d’une même structure, différents emplacements spécifiques ou non d’une même catégorie sémantique (structure d’extraction combinée, multi-slot, cf. figure 1.1 page précédente), d’autres en sont incapables (structure d’extraction simple, single-slot, cf. figure 1.2 page §). Cela peut dans certains cas se révéler handicapant pour le système lorsque les relations entre différents emplacements peuvent les distinguer. L’exemple de la figure 1.2 page § montre bien le problème qui peut découler d’une structure d’extraction simple : on ne peut déterminer d’après la structure le poste quitté ou le nouveau poste, ni la société à laquelle ces postes sont reliés.
|
Input : Mr. Adams, former president of X Corp., was
named CEO of Y Inc.
|
Toutefois, les structures d’extraction simple s’avèrent adéquates dans les cas où une seule information de chaque catégorie est présente dans un texte distinct. Ce présupposé limite donc ce type d’extraction aux textes structurés et, éventuellement, aux semi-structurés, où l’information est plus prévisible qu’en texte libre.
On pourrait s’étonner de notre intérêt pour les approches des textes structurés ou semi-structurés. En effet, nous travaillons sur une encyclopédie dont le texte est libre. Toutefois, puisqu’une certaine quantité d’information est balisée – et donc partiellement structurée – et identifiée selon une définition de type de document (Document Type Definition, DTD) XML, il nous a semblé pertinent de ne pas rejeter a priori les méthodes qui permettent de traiter le texte structuré.
Avec Wrapper Induction [Kushmerick et al., 1997], nous nous intéressons à un système d’extraction d’information destiné à traiter des données structurées dans des tableaux et à en identifier les éléments en conservant leur cohérence avec les autres composants d’un même tableau. Ce système est typiquement voué à gérer des pages Web. De ce fait, son domaine d’application peut s’ouvrir à une extraction combinée autant qu’à une extraction simple, pour autant que les textes qui lui sont présentés soient résolument structurés.
Ce système repose sur l’utilisation de wrappers, c’est-à-dire de procédures logicielles spécifiques à un type de structure de ressource informationnelle, et qui traduisent la réponse à une requête donnée en un nouveau canevas d’information simple ou combinée selon la structure de base du document et le sujet de l’information sélectionné. Ce canevas identifie et, le cas échéant, combine les différents éléments d’une information de sujet prédéterminé.
Toutefois les wrappers sont généralement construits manuellement. L’originalité de [Kushmerick et al., 1997] réside donc dans la proposition d’une méthode inductive qui permet d’apprendre automatiquement l’organisation de documents dont l’information, combinée ou non, a été préalablement étiquetée. De la sorte, une information pourra être extraite de documents présentant une information de même nature et une structure de même type que celles des documents qui ont servi à générer le wrapper.
Ces wrappers reposent sur la génération de règles HLRT (pour Head Left Right Tail), dont le principe consiste à identifier les bornes gauche et droite de chaque élément d’information. La détermination de la structure d’en-tête et de fin de page permet en outre de ne pas limiter le nombre des canevas informatifs dans la page. En effet, aussi longtemps que la structure de fin de page n’est pas détectée, un canevas informationnel complet est susceptible d’être suivi par un autre, délimité lui aussi par les mêmes bornes.
|
|
|
Congo
242 Egypt 20 Belize 501 Spain 34
|
L’exemple 1.4 page § illustre bien le fonctionnement du wrapper. Il parcourt le texte jusqu’à la borne de fin d’en-tête <P> mais n’en retient rien. Une fois cette borne dépassée, il recherche une borne d’information gauche (<B> ou <I>), à partir de laquelle il extrait l’information jusqu’à la borne droite correspondante suivante (</B> ou </I>), et imprime l’information extraite. Il reprend ensuite cette opération de recherche - extraction - impression jusqu’à la première occurrence de la borne initiale de fin de page (<HR>) qui marque la fin de la zone informative pertinente de la page et arrête le wrapper pour cette page. On obtient donc la liste des éléments d’informations compris entre les bornes <B> et </B>, <I> et </I> du corps de la page, à l’exclusion de l’en-tête et du bas de la page.
Cette méthode présente l’avantage d’une grande fiabilité : en effet, lorsque la structure du document traité est commune avec celle du corpus d’apprentissage, elle extrait sans difficulté toute l’information jugée pertinente lors de l’inférence du wrapper. D’autre part, son fonctionnement par bornes basées sur les balises d’un langage structuré s’applique bien à la partie la plus structurée des articles de l’encyclopédie que nous avons pour tâche de traiter, d’autant plus que l’information est identifiée et que sa structure, bien que variable, est figée dans la définition de type de document (DTD, Document Type Definition).
Toutefois, hors du cartouche d’en-tête de chaque article encyclopédique, le texte devient libre et ce type d’approche montre alors sa limite. De plus, malgré une structure relativement rigide quant au balisage, l’information-même contenue dans les balises conserve une certaine latitude de présentation que le wrapper ne peut gérer du fait de sa grande rigidité, du fait aussi qu’il ne tient absolument pas compte du contenu informatif du texte qu’il a pour charge d’extraire, mais qu’il s’arrête au repérage des bornes sans s’occuper de l’information elle-même 4. Enfin, le fait que nous disposions de la DTD qui a servi à constituer l’encyclopédie rend redondante un travail d’induction sur sa structure déjà connue.
|
Dès lors, deux options se présentent à nous : soit utiliser une autre technique de gestion de l’information pour la partie la plus structurée de chaque article, soit ajouter au wrapper de [Kushmerick et al., 1997] une méthode qui permettrait de pénétrer à l’intérieur de l’information, ou en tout cas un traitement postérieur à son extraction.
La seconde approche permettant d’effectuer une extraction d’information sur des textes structurés est WHISK [Soderland, 1999]. Basé sur la technologie des expressions régulières (Regular Expressions), cette méthode ne se limite pas aux textes formatés mais, plus souple que Wrapper Induction, elle traite également les documents semi-structurés. De plus, sous une forme étendue et plus évoluée, elle aborde également le texte libre. Nous nous limitons ici aux textes structurés et semi-structurés, pour lesquels la démarche reste la même. Nous aborderons le traitement du texte libre dans la section 1.2.4 page §.
Comme pour Wrapper Induction, le principe de cette méthode est d’identifier, dans des textes pré-étiquetés, le contexte direct de l’information désignée comme pertinente, et en particulier les délimiteurs de cette information, pour constituer des règles d’extraction. Dans WHISK, ces règles se présentent sous forme d’expressions régulières constituées en patrons. Un patron correspond à une ou plusieurs expressions régulières, dont chaque mémorisation coïncide avec un élément de l’information pertinente que le patron doit fournir.
Les expressions régulières conviennent bien pour définir de tels patrons. En effet, elles sont capables de décrire rigoureusement les délimiteurs de l’information, mais elles présentent également l’avantage de pouvoir assouplir les contraintes sur ces délimiteurs, et même sur le texte compris entre les délimiteurs si cela est nécessaire. De plus, il est possible de définir plusieurs champs d’extraction dans une même expression régulière, et donc d’effectuer une extraction combinée.
Les règles définies par [Soderland, 1999] présentent toutefois quelques particularités si on les compare aux expressions régulières classiques définies par [Aho et Ullman, 1973, Aho et al., 1988]. Essentiellement, les quantificateurs (« * » et « + ») sont non gourmands, c’est-à-dire que leur étendue de fonctionnement n’est pas la plus longue possible. Cela permet de favoriser la proximité entre les éléments d’une même information dans le cadre d’une extraction combinée, et de limiter le temps de traitement du document en évitant de tenter des mises en correspondance très longues.
|
D’autre part, la capacité des expressions régulières à manipuler des classes de caractères (par exemple [a-z], [0-9]...) a été étendue de manière à ce que des classes de mots puissent être utilisées. Il est donc possible de définir des ensemble de mots jugés équivalents et de les regrouper sous une seule appellation, un mot-clef qui apparaît en italiques dans le patron d’extraction. Dans l’exemple 1.7 page précédente, le patron d’extraction comporte un Digit qui représente un chiffre, et un Number qui désigne un nombre d’un chiffre ou plus.
Les règles d’extraction de WHISK fonctionnent comme suit : lorsque chaque élément mémorisé par le patron correspond à une portion du texte, ces éléments sont mémorisés ; si le texte n’est pas entièrement parcouru par le patron qui s’est appliqué, la même règle d’extraction est appliquée à la portion du texte restante (dans l’exemple, un même patron est appliqué deux fois) ; lorsqu’il y a échec d’un patron, mais que des éléments de la règle ont pu être identifiés, on conserve ces éléments et on relance la même règle sur le texte au-delà des éléments identifiés pour éviter de mélanger des éléments d’information distincts.
Les particularités des règles de WHISK permettent de gérer dans une certaine mesure la sémantique dont peut être porteur le texte structuré ou semi-structuré, et donc de faire face aux variations qui lui sont propres. En effet, la possibilité de manipuler des classes de mots permet de se détacher de la contrainte lexicale pour se concentrer sur des éléments linguistiques de plus haut niveau. Cela permet également de généraliser les règles bien plus aisément que ne l’autorise Wrapper Induction. D’autre part, l’utilisation des expressions régulières dans les patrons d’extraction permet d’appliquer des contraintes plus variées que les règles HLRT de Wrapper Induction, et notamment de tenir compte du contenu-même des groupes de mémorisation, comme c’est le cas pour le nombre des chambres et le prix de location dans l’exemple. Les expressions régulières sont donc bien plus adaptées que ces règles à l’extraction d’une information certes balisée, mais irrégulière à l’intérieur des balises. Cette constatation est intéressante car les outils dont nous disposons permettent de manipuler des expressions régulières. Il ne s’agit toutefois que de reconnaître une information pertinente dans un texte à partir de patrons, et pas encore d’identifier un sens ou une signification dans ce texte.
Comme WHISK, l’approche de [Freitag, 1998] permet de traiter des
documents qui ne suivent pas les règles grammaticales d’une langue, qu’ils
soient structurés ou semi-structurés. Elle repose sur la mise en œuvre
de trois stratégies d’extraction de l’information et se concentrent sur
un seul champ d’extraction. Il s’agit donc d’une extraction simple. Le
principe de fonctionnement de cette approche est le suivant : tous les
fragments 5
du texte sont considérés comme des réponses possibles depuis les plus petits
(avec comme limite le nombre de mots de la réponse la plus courte dans le corpus
d’entraînement) jusqu’au plus grand (avec comme limite le nombre de
mots de la réponse la plus longue). Un indice de confiance est appliqué à
chacun des groupes selon les trois méthodes suivantes. La plus simple des
méthodes d’extraction exploitée consiste à mémoriser par une procédure
rudimentaire d’apprentissage par cœur (rote learner), dans le corpus
d’entraînement, le fragment de texte constituant la réponse à la requête
prédéfinie afin de construire un dictionnaire d’exemples de réponses. Pour la
perfectionner et donner à chaque fragment une pondération de confiance,
on estime la probabilité P pour chaque fragment f d’être une réponse
pertinente à la requête (Rf est le nombre d’apparition du fragment de texte
dans une réponse ; Tf est le nombre d’apparition total du fragment de
texte) :
P(f) = 
L’ajout de 1 au dividende et de 2 au diviseur s’explique par le fait qu’il ne faut pas exclure la possibilité statistique qu’un fragment de texte soit une réponse pertinente à une requête proposée simplement parce que ce fragment n’apparaît pas dans les réponses du corpus d’entraînement ou même dans le corpus d’entraînement lui-même (formule de Laplace). Ainsi, P(f) correspondra à une fraction de 1 si f n’est pas une réponse pertinente dans le corpus d’entraînement, et P(f) aura une valeur de 0.5 si ce même énoncé f n’apparaît pas dans le corpus, ce qui équivaut à ne pas prendre de décision.
La deuxième méthode, héritée de la classification de documents, est une
généralisation de la stratégie précédente. Mais, basée sur l’utilisation de la
formule de la probabilité des causes de Bayes (Bayes learner), elle permet de
tenir compte de son environnement lexical puisqu’elle attribue à chaque mot une
probabilité d’appartenir à une réponse en fonction de son contexte, chaque
réponse du corpus d’entraînement étant considéré comme un sac de
mots (bag-of-words). Chaque fragment d’un texte est considéré comme
une hypothèse (H) à vérifier et son environnement (D) influe sur sa
pertinence :
P(Hi|D) = 
Ces deux approches présentent peu d’intérêt pour le problème qui nous occupe, puisqu’elles se bornent à exploiter des données statistiques et des mesures de fréquences. La troisième méthode présentée par [Freitag, 1998] (SRV, relational learner) tient compte quant à elle d’indices linguistiques (syntaxe, morphologie) en plus d’autres caractéristiques (présentation du document). Ces traits sont appelés simples s’ils s’appliquent à un seul mot (par exemple capitalized ? ou noun ?) et relationnels s’ils concernent le comportement d’un mot vis-à-vis d’un autre (par exemple next-token ou subject-verb). Il est dès lors possible d’induire des règles relationnelles dont ils constituent les contraintes.
L’exemple 1.8 page ci-contre présente une règle qui recherche un ou des éléments A précédés par un mot en capitales deux mots plus tôt dans le texte.
La méthode du système la plus proche de nos préoccupations linguistiques est SRV, qui génère des règles de contraintes pour effectuer l’extraction. Elle est intéressante dans son approche de traits à la fois de nature linguistiques et autres, comme la présentation typographique, mais reste limitée à une extraction simple et nous ne voyons pas comment la perfectionner pour l’ouvrir à une extraction combinée. D’autre part, les règles relationnelles ne présentent pas une grande originalité par rapport aux patrons que l’on a observés dans le système WHISK. En effet, les expressions régulières sont à même de prendre en compte les mêmes indices tout en conservant une extraction combinée. De plus, elles constituent depuis longtemps un standard dans le monde de l’informatique, et plus particulièrement dans celui du traitement automatique des langues. Il ne s’agirait donc pas d’implanter un formalisme neuf, ce qui constitue un grand avantage pratique. Toutefois, [Freitag, 1998] suggère à bon escient une approche multistratégie du problème car il est difficile de traiter de même façon du texte grammatical et de l’information structurée.
[Califf et Mooney, 1997, Califf et Mooney, 1999] décrivent Rapier (Robust Automated Production of IE Rules), un système de génération de règles d’extraction destiné, dans son état actuel, à du texte qui ne respecte pas la grammaire d’une langue. Les règles d’extraction de Rapier utilisent des patrons qui exploitent des indices syntaxiques limités (partie du discours) et sémantiques (lexique sémantique tel que WordNet [Fellbaum, 1998b]). On repère dans chacun des textes du corpus d’entraînement l’information qui correspond à un champ d’extraction et de ce fait on divise le texte en trois partie :
Les règles de Rapier sont des patrons d’extraction correspondant à ces différents champs. D’un point de vue lexical, le patron correspond à une liste plus ou moins longue de lexèmes appartenant à chacun des champs (on peut faire varier ce nombre). Les indices syntaxiques et sémantiques sont ajoutés au patron selon qu’ils correspondent ou non aux listes extraites pour chacun des champs. Le type de règles mises en œuvre ne permet pas d’effectuer une extraction combinée (puisqu’il n’y a qu’un champ informatif) et il semble que le perfectionnement de cette approche demande une importante complication de la méthode.
|
L’exemple 1.1 page précédente montre une règle construite par Rapier pour extraire le nombre de transactions indiqué dans des communiqués concernant des acquisitions d’entreprises. Cette règle extrait la valeur undisclosed de phrases telles que sold to the bank for an undisclosed amount ou paid Honeywell an undisclosed price. Le patron qui précède la réponse contient deux éléments : un mot dont la catégorie grammaticale est soit un nom (nn) soit un nom propre (nnp), et une liste de deux mots au moins sans contrainte. Le patron d’extraction contient le mot undisclosed étiqueté comme adjectif (jj). Le patron suivant la réponse requiert un mot dont la catégorie sémantique (dans WordNet) est price.
Le format des règles d’extraction de Rapier impose un nouveau patron pour chaque type d’information à identifier, ce qui n’autorise pas d’extraction de données combinées. D’autre part, bien que la procédure reste sensiblement la même que dans les autres méthodes observées (contraintes diverses sur les bornes gauche et droite de l’information, ainsi que sur le champ informatif lui-même), le formalisme de la règle est encore une fois spécifique à l’application et ne présente pas la même souplesse que les expressions régulières standard, sans pour autant offrir de fonctionnalité particulière. Comme ses homologues, Rapier demande une phase d’apprentissage sur un corpus d’entraînement étiqueté, et se limite à des requêtes prédéfinies.
Les systèmes d’apprentissage de règles d’extraction pour le texte libre sont assez rares et se cantonnent souvent à une désambiguïsation sémantique lexicale locale au mot, ou à une étude statistique du lexique des documents [Sheridan et Ballerini, 1996, Gaussier et al., 2000]. D’autres approches nous intéressent, plus proches de l’étude linguistique du texte. Ce sont ces approches que nous présentons ici.
Une des premières approches à dominante linguistique en extraction d’information s’est effectuée au travers de l’analyseur conceptuel CIRCUS [Lehnert, 1990]. Il s’agit d’un outil d’analyse de texte qui se base à la fois sur une analyse syntaxique sommaire (ni arbre, ni grammaire) et sur un dictionnaire de nœuds de concept (concept nodes) pour produire sous forme d’un tableau d’information (case frame) une représentation sémantique d’un texte présenté en entrée.
Chaque entrée de ce dictionnaire de nœuds de concept décrit un événement, c’est-à-dire qu’il définit les contraintes syntaxiques et sémantiques (lexicales) qui doivent être remplies par le texte pour correspondre à cette entrée. On dit qu’une entrée est activée lorsque le texte remplit les contraintes qu’elle fixe. Un tableau informationnel est la structure de l’information du texte telle qu’elle se présente lorsque un ou des nœuds conceptuels ont été activés.
|
Sentence :
Two vehicles were destroyed and an unidentified office of the agriculture and livestock ministry was heavily damaged following the explosion of two bombs yesterday afternoon.
|
Dans l’exemple 1.9 page ci-contre, la phrase déclenche trois nœuds conceptuels du dictionnaire : la construction passive du verbe to destroy permet d’en identifier le sujet comme cible de destruction ; la construction passive du verbe to damage permet également d’en sélectionner le sujet comme cible ; enfin, le mot bomb est lexicalement identifié comme une arme. À partir de ces nœuds déclenchés, le case frame correspondant peut recevoir diverses informations : les signatures (constructions relatives aux déclencheurs) ainsi que les cibles et l’instrument.
Il faut cependant noter que CIRCUS réclame un dictionnaire de nœuds de concept spécialisé pour chaque domaine d’extraction. [Riloff, 1993] note que ce dictionnaire de nœuds de concept est extrêmement long à réaliser (environ 1 500 heures/personne) et qu’il est utopique de croire pouvoir en obtenir un pour chaque domaine dans lequel on voudrait réaliser de l’extraction d’information, ce qui réduit la portabilité de CIRCUS. Aussi Ellen Riloff propose-t-elle le système AutoSlog [Riloff, 1993, Riloff, 1996b, Riloff et Shepherd, 1997] capable, à partir d’un corpus représentatif d’un domaine, de construire un dictionnaire de nœuds de concept spécialisé de ce domaine. Cette approche repose sur deux observations :
Il ressort de ces observations que la mise en exergue d’une dépendance syntaxique entre deux termes laisse supposer un rapport sémantique entre ces mêmes termes.
Pour concevoir un dictionnaire des nœuds de concept représentatif d’un domaine, le corpus d’apprentissage doit identifier les éléments de l’information appropriée pour remplir un case frame donné correspondant à l’information pertinente du domaine. Pour chaque texte de ce corpus, les éléments d’information en sont listés et identifiés. Ainsi, si la phrase de l’exemple (cf. figure 1.9 page précédente) appartient à un document d’un tel corpus, certains éléments en seront identifiés et typés par un spécialiste comme étant pertinents pour la recherche d’information pour le domaine des attaques terroristes : two vehicles et an office of the agriculture and livestock ministry sont des cibles (targets), tandis que bombs est un instrument.
À l’aide du corpus d’entraînement ainsi traité, AutoSlog va générer les nœuds de concept selon la démarche qui suit :
|
Avec AutoSlog, nous avons la présentation d’un système de génération de règles d’extraction basé sur les relations syntaxico-sémantiques entre les mots tout en privilégiant les données lexicales à travers l’extraction de données d’un corpus d’entraînement. De la sorte, l’utilisation d’une ressource lexicale indiquant la sémantique des mots et leur construction syntaxique se révèle attrayante et intéressante. [Soderland, 1999] émet des réserve sur le niveau de précision de la réponse fournie par AutoSlog, qui se contente de restituer des groupes syntaxiques complets. Cette réticence n’a pas de raison d’être dans notre approche, qui cherche à fournir une réponse au niveau de la phrase, du paragraphe voire du document si les éléments informatifs recherchés sont disséminés dans plusieurs phrases.
Cependant, la limitation du champ d’application d’AutoSlog à une seule information par document du fait d’un mode d’extraction simple en réduit grandement la portée. De plus, même si la création du dictionnaire lors de la mise en œuvre d’AutoSlog est infiniment plus rapide que la construction manuelle d’une telle ressource 7, il demeure qu’un travail important doit être mené sur le corpus d’entraînement lui-même. Ce travail n’entre pas dans la comptabilisation de [Riloff, 1993], alors qu’il relève d’un spécialiste et ne peut être mené très rapidement.
Cette remarque n’a pas échappé à l’attention des concepteurs d’AutoSlog : en effet, [Riloff, 1996a] note que 50 heures/personne environ sont nécessaires pour annoter 1000 documents. [Riloff, 1996a, Riloff et Lorenzen, 1999] définissent un nouveau système, AutoSlog-TS, qui peut se contenter d’exploiter un corpus représentatif d’un domaine, avec la seule indication de présence ou non d’une information pertinente dans chaque document afin d’éviter les problèmes liés à la conception d’un corpus étiqueté. Cependant le système devient alors un simple catégoriseur de documents, et quitte dès lors notre champ d’intérêt car il n’est plus capable d’extraire une information précise.
Avec CRYSTAL, [Soderland et al., 1995] s’inscrivent bien dans la continuité des travaux menés par [Riloff, 1993] pour AutoSlog. En effet, CRYSTAL repose également sur l’utilisation d’un système d’extraction d’information qui s’appuie sur un dictionnaire de nœuds conceptuels. Ce système d’extraction est un analyseur de phrases appelé BADGER, qui a succédé a CIRCUS a l’Université du Massachusetts. De la même manière que le système AutoSlog aussi, CRYSTAL repose sur le principe de la construction automatisée d’un dictionnaire de nœuds conceptuels à partir d’un ensemble manuellement préétiqueté d’exemples d’informations pertinentes dans le domaine visé.
Ces nœuds conceptuels ont toutefois évolué depuis ceux de CIRCUS : moins soumis à des types d’information prédéfinis, ils s’appuient sur une caractérisation de l’information locale au nœud, et plus à une caractérisation attachée au dictionnaire dont il fait partie. D’autre part, l’extraction combinée est maintenant possible. L’exemple (cf. figure 1.10 page §) indique les différentes fonctionnalités qui leur ont été ajoutées.
|
Sentence :
Unmarkable with the exception of mild shortness of breath and chronically swollen ankles.
|
D’autre part, le système BADGER permet d’exploiter plus profondément la syntaxe puisque les possibilités d’analyse ont été grandement améliorées depuis le précédent système.
Mais la principale amélioration de CRYSTAL repose dans sa faculté à généraliser les nœuds de concept extrêmement contraints qu’il extrait dans un premier temps. En effet, l’algorithme qui le pilote permet d’étendre ces contraintes tant sémantiques que syntaxiques au maximum, la limite étant la possibilité d’exploiter toujours avec la même efficacité le corpus d’entraînement qui lui est utile pour créer son propre dictionnaire de nœuds de concept. L’algorithme que nous reprenons ici (cf. figure 1.11 page §) indique de quelle manière le système procède.
|
Ce système, bien que présentant les avantages de la généralisation automatique et de l’extraction combinée par rapport au précédent système, n’apporte pas d’avancée significative dans le domaine de l’exploitation de l’information. Tout au plus valide-t-il l’utilisation d’une étude syntaxique plus évoluée et plus approfondie.
WHISK est le seul système conçu pour traiter à la fois les documents structurés ou semi-structurés et le texte libre. Si son approche du texte libre subit des changements par rapport aux autres types de textes, le principe de fonctionnement de l’application reste le même.
En effet, c’est toujours une étude du contexte de l’information étiquetée qui permet la constitution de patrons sous forme d’expressions régulières. Toutefois, à l’image d’AutoSlog et de CRYSTAL, WHISK intègre une analyse syntaxique des énoncés qui permet d’identifier les rapports syntaxique de l’information avec son contexte et d’ajouter ce critère aux contraintes du patron.
La phase d’apprentissage au cours de laquelle sont construites les règles n’est toutefois pas complètement automatique. En effet, les textes (étiquetés) ne sont pas présentés tels quels au système. Un prétraitement est généralement nécessaire, notamment pour effectuer une segmentation. Les textes présentés à WHISK en sont des extraits correspondant à un exemple d’information par extrait.
|
Énoncé :
C. Vincent Protho, chairman and chief executive officer of this maker of semiconductors, was named to the additional post of president, succeeding John W. Smith, who resigned to pursue other interests. Analyse syntaxique :
Règle correspondante :
| |||||||||||||||||||||||||||||
La figure 1.12 page précédente présente un exemple de formation de règle d’extraction à partir d’un exemple en texte libre. L’analyse syntaxique de cet exemple permet de distinguer les champs syntaxiques (SUBJ pour sujet, VB pour verbe principal, PP pour groupe prépositionnel et REL_V pour proposition relative rattachée à un verbe). Les indications précédées par @ sont d’ordre sémantique (PN pour nom de personne, PS pour poste, CN pour nom de société), syntaxiques (Passive pour passif) ou morphologiques (la racine d’un verbe : nam, succeed, resign, pursu). La règle qui en découle est une expression régulière. Les mots en italiques indiquent des classes sémantiques. Les @ permettent de requérir une indication morphologique (@succeed demande un verbe de radical succeed) ou syntaxique (@Passive exige un verbe à la voix passive). Le quantifieur * permet de ne pas prendre en considération un nombre illimité de caractères. S’il est suivi de F (*F), la fin du champ syntaxique sert de limite aux caractères dont il ne faut pas tenir compte.
L’application de telles règles requiert une analyse syntaxique des textes à traiter. Toutefois, les exigences syntaxiques présentes dans les règles peuvent être désactivées, et dès lors la règle fonctionnera comme pour du texte semi-structuré. Notons encore que les classes sémantiques ne sont pas toujours suffisantes pour identifier certaines entités. Des listes d’entités nommées et des stratégies de reconnaissance de ces entités peuvent être mises en œuvre pour les reconnaître.
Suite au succès rencontré par MUC, diverses autres conférences ont vu le jour, qui abordent des disciplines semblables ou connexes à l’extraction d’information. En particulier, la campagne d’évaluation TREC (Text REtrieval Conference) a obtenu un consensus dans le domaine de la recherche d’information. TREC fait actuellement autorité pour tester la valeur des approches qui visent à la sélection de documents qui contiennent une information déterminée. Les systèmes qui concourent cherchent en effet à déterminer dans une base documentaire les documents qui correspondent à une information réclamée par un utilisateur [Harman, 1992].
Au cours des éditions successives de TREC 8, différentes tâches ont été définies qui répondent à des besoins réels d’application réclamées par le public. Ces tâches correspondent à différentes facettes de la gestion de l’information.
Les mesures d’évaluation des systèmes présentés dans les campagnes d’évaluation TREC correspondent aux mesures traditionnelles de rappel et de précision, qui sont par ailleurs utilisées dans le cadre des conférences MUC (cf. section 1.2.1 page §). Seule la tâche de question-réponse, très particulière, fait exception car le rappel n’a pas été jugé prépondérant pour ce type d’application. C’est donc un score correspondant au rang de la première bonne réponse pour chaque question qui indique la qualité du système. Par ailleurs, les lacunes du système sont indiquées par le nombre de questions qui n’obtiennent pas de bonne réponse (cf. section 7.2.2 page §).
Parmi les différentes perspectives offertes par TREC, c’est la tâche de question-réponse qui a particulièrement retenu notre attention. En effet, contrairement aux autres, elle exige une fenêtre de réponse inférieure au document entier et réclame une identification plus ou moins exacte de l’information recherchée 9. De plus, les questions ne sont pas limitées à une information ou à un type d’information. Dès lors, la tâche de question-réponse affirme résolument son caractère généraliste. Ces deux caractéristiques particulièrement exigeantes nous amènent à nous intéresser à la tâche de question-réponse comme nous l’avons fait pour celle d’extraction d’information.
Notre propos n’est pas ici d’étudier les méthodes de question-réponse existantes, mais plus élémentairement les techniques qui permettent d’identifier une information et de la traiter, avant toute localisation d’informations correspondantes dans les textes et dans les requêtes. L’objectif de notre thèse est en effet d’élaborer une méthodologique de construction d’une structure informationnelle à partir d’une base documentaire. Cette structure informationnelle doit permettre de gérer l’information contenue dans la base documentaire quels que soient les besoins de l’utilisateur. L’interrogation particulière de la base documentaire constitue une évaluation de la qualité de la structure, mais elle reste partielle et dirigée. Le but est en effet d’obtenir une méthodologie généraliste reposant sur des méthodes linguistiques.
Dès les années septante, la problématique de question-réponse a été envisagée et traitée grâce à des approches de type linguitique. À cette époque, le genre des textes et le domaine auquels ils appartenaient étaient extrèmement spécifiques. Par exemple, le système QALM [Lehnert, 1977, Lehnert, 1979] analyse de courtes histoires sur des sujets très précis et limités pour en extraire une représentation conceptuelle. Le système QALM dispose en outre d’une base de connaissances propres au domaine du scénario analysé, ainsi que d’une typologie des questions disposant de 13 catégories de question qui possèdent leur propre heuristique pour trouver la réponse à la question proposée. Ces heuristiques reposent sur une analyse du contenu de la question, sur une recherche dans la représentation conceptuelle du scénario et sur un raisonnement à partir de la base de connaissances.
Les systèmes ultérieurs ne différent de QALM que par une extension des connaissances, surtout pragmatiques, de l’univers appréhendé, et par une plus grande variété de types de questions [Dyer, 1983, Zock et Mitkov, 1991]. Le système QUEST [Graesser et al., 1994], qui correspond à la même approche, définit les quatre composantes de ce type d’architecture :
[Ferret et al., 2002a] estime que cette architecture exclusivement linguistique n’est pas réalisable pour une application généraliste car les sources d’information devraient alors comprendre une définition et une formalisation des connaissances pragmatiques sans limite de domaine. [Mollá Aliod et al., 2000] ne dit pas autre chose lorsqu’il utilise un modèle semblable pour poser des questions sur les commandes UNIX, tout en adjoignant à une analyse syntaxico-sémantique un raisonnement logique reposant sur des inférences liées à un lexique limité par le domaine et à des connaissances sémantiques du domaine.
Et en effet, depuis la première édition de TREC, la plupart des systèmes de question-réponse généralistes sont basés sur une architecture légèrement différente :
Les différences reposent essentiellement dans les traitements d’analyse de la question et dans ceux des textes. Les traitements appliqués à la question sont propres aux méthodologies de question-réponse. Les procédés appliqués aux textes présélectionnés correspondent à un traitement de l’information contenue dans ces textes. Le moteur de recherche permettant de sélectionner les textes candidats n’appartient pas à la méthodologie de question-réponse, mais les processus utilisés pour sélectionner des documents qui ne contiennent pas forcément les unités lexicales contenues dans l’information extraite de la question ne doivent pas être négligés.
Dès la première évaluation des systèmes de question-réponse dans TREC [Voorhees, 1999], cette architecture a été mise en œuvre. Par exemple, le système de [Hull, 1999] analyse les questions pour en extraire le vocabulaire et pour en catégoriser l’objet grâce à l’interrogatif et à certains patrons lexicaux 10. Le vocabulaire ainsi extrait permet de constituer un ensemble de textes qui lui correspondent grâce au système d’extraction d’information de AT&T.
Les textes extraits sont analysés et chacune des phrases de ces textes sont classifiées en fonction du nombre de mots qu’elles contiennent en commun avec la question. Les noms propres et les nombres reçoivent le poids le plus important, puis les noms communs ou inconnus. Les autres mots sont peu considérés. L’application d’un module de reconnaissance d’entités (ThingFinder [Trouilleux, 1998]) permet ensuite d’identifier les noms de personne, de lieu, les expressions de date, de prix, de quantité ou de nombre. Ces entités sont mises en correspondance avec le type de la question et les phrases qui ne contiennent pas le type attendu sont éliminées. Les mots ou expressions qui correspondent au type de la question sont considérés comme des réponses potentielles. Le vocabulaire contenu dans la question est éliminé.
Les résultats obtenus par ce système sont relativement honorables. Toutefois, l’auteur regrette à plusieurs reprises les erreurs que le manque de traitements linguistiques ne permet pas de corriger. Notamment, lors de son analyse des phrases sélectionnées, il déplore le manque de liens entre les réponses possibles et le contenu de la question. Par ailleurs, l’analyse de la question elle-même demande des ressources sémantiques dont le système ne dispose pas.
L’évolution des méthodes de question-réponse depuis la huitième édition de TREC en 1999 n’a pas modifié l’architecture générale des systèmes, qui sont toujours basés sur une catégorisation des requêtes, sur une recherche par mots-clefs dans les documents à l’aide d’un moteur de recherche généralement externe et sur des traitements des documents sélectionnés par le moteur pour en identifier ou en extraire la meilleure réponse. Le système QALC de [Ferret et al., 1999, Ferret et al., 2002b] s’appuie sur la constatation que les méthodes qui comportent les traitements linguistiques les plus élaborés sont également ceux qui atteignent les meilleures performances. Dès lors, et pour chaque partie du système, les traitements linguistiques sont privilégiés dans cette approche.
Tout d’abord, l’analyse de la question doit permettre d’obtenir deux informations. D’une part c’est grâce à elle qu’est atteinte la catégorisation de l’objet de la question, et donc de la réponse attendue. Cette catégorisation est réalisée par des patrons qui s’appuient sur des critères lexicaux (principalement la nature de l’interrogatif), syntaxiques (la catégorie syntaxiques des groupes en relation syntaxique directe avec l’interrogatif) et sémantiques (des catégories sémantiques fournies par WordNet). L’application d’un patron de catégorisation identifie la catégorie de la réponse attendue à la question parmi quinze étiquettes qui correspondent aux entités nommées. D’autre part, l’analyse de l’énoncé de la question permet d’identifier les mots qui la constituent, et plus particulièrement des expressions syntaxiques complexes, appelées termes de recherche 11. Ces termes et mots sont appelés à servir de mots-clefs lorsque le moteur effectue sa recherche.
Si le choix d’un moteur de recherche dans le cadre de cette application est basé sur la capacité de ce moteur à fournir une bonne réponse dans le plus grand nombre de cas par rapport à ses concurrents ainsi qu’à présenter le plus grand nombre de bonnes réponses, il repose également sur son aptitude a prendre en compte divers phénomènes linguistiques, et notamment la synonymie et des techniques de racinisation (stemming). L’ensemble de l’information extraite de la requête est donc exploitée pour sélectionner des documents contenant les mêmes données et donc susceptibles de contenir la réponse.
Enfin, divers traitements sont appliqués aux documents proposés par le moteur de recherche afin de déterminer plus précisément la réponse à la question et pour classifier les propositions de réponse en fonction du degré de similitude de la proposition avec l’énoncé de la question. Le premier traitement est effectué par l’analyseur transformationnel Fastr [Jacquemin, 1999] qui permet d’envisager un grand nombre de variations morphologiques (les mots de même racine que l’unité originale) et sémantiques (les mots contenus dans un ensemble synonymique (synset) de WordNet 1.6 où apparaît l’unité originale) de la question. Notons ici qu’aucune désambiguïsation sémantique n’est appliquée et que tous les synsets sont considérés. À partir des familles morphologiques et sémantiques, des patrons sont constitués qui peuvent identifier l’expression originale de la question et ses variation présentes dans les textes. Il est dès lors possible d’affecter un poids à chaque document, qui est fonction inverse de son degré de variation par rapport à l’énoncé de la question. La présence de noms propres et celle des termes les plus longs sont deux facteurs qui augmentent le poids accordé à un document. Les vingt documents les plus pertinents sont classifiés et conservés.
Le deuxième traitement consiste à déceler les entités nommées (personnes, organisation, lieux, valeurs) au sein des documents de la sélection. Pour ce faire, QALC exploite divers dictionnaires d’entités nommées, des lexiques sémantiques dont il adapte l’information et des règles dédiées à chaque type d’entité, utilisées lorsque les lexiques sont lacunaires. Au niveau numérique, ces règles distinguent les nombres cardinaux et ordinaux, les expressions complexes « nombre-unité » (distances, valeurs monétaires,...), les expressions de temps et les autres nombres. Les organisations sont dénotées par la présence d’unités lexicales déterminées (Administration, Association,...) tandis que les noms de personnes correspondent à des patrons lexicaux (Dr, President,...) ou typographiques (majuscules,...). L’identification de ces entités correspond à la catégorisation des questions.
Enfin, l’appariement de la question avec la réponse se fait au niveau de la phrase, qui présente une réponse courte dans un contexte suffisant pour juger de sa pertinence. Chaque phrase de chaque document proposé reçoit un score d’appariement en fonction de trois critères : la présence de mots simple de la question dans la phrase, la présence de termes ou d’une de leurs variantes dans la phrase, la présence des entités nommées dans la phrase. Chaque type d’entité présente à la fois dans la question et dans la phrase reçoit un poids qui lui est propre et le poids de chaque phrase correspond à la combinaison des poids de chaque type, les mots simples valant deux fois les termes et les entités nommées. Toutefois, une proposition dans laquelle aucune entité ne correspond à la catégorie de la question est éliminée. La réponse la plus pertinente est celle dont le poids est le plus élevé.
Le système qui obtient les meilleurs résultats dans les différentes évaluations TREC des systèmes de question-réponse est aussi celui qui utilise les procédures d’analyse linguistique les plus élaborées. Il s’agit du système Falcon [Moldovan et al., 2000, Harabagiu et al., 2000]. Comme les autres systèmes de question-réponse, cette application procède en trois étapes : catégorisation de la question, application d’un moteur de recherche sur les documents, analyse des réponses proposées pour déterminer un ordre de pertinence.
D’abord, un analyseur probabiliste est chargé de repérer les dépendances entre les mots de la question. Le résultat de cette analyse permet de reformuler la question sous la forme d’un graphe relationnel qui relie les têtes de groupes. Ces dépendances sont anonymes, ce qui ne permet pas de juger de leur importance. Ce graphe, ou formulaire sémantique – car les unités lexicales sont reliées à la taxinomie de WordNet – permet non seulement d’identifier le type de la question (la tête qui à la plus grande connexion syntaxique), mais aussi les mots-clefs qui sont utilisés par le moteur de recherche (les noms directement reliés au type ainsi que les adjectifs et les adverbes). Le type lui-même appartient à une des 27 catégories d’entités nommées, traduite dans un des 15 nœuds hiérarchiques supérieurs de WordNet pour la recherche. Aucune désambiguïsation sémantique n’est effectuée.
Trois types d’alternances sont prévus pour pallier les variations de la réponse par rapport à la question. L’alternance peut être morphologique (flexions et dérivations de mots-clefs), lexicale (utilisation de synonymes) ou sémantique (termes semblables sans être synonymes, hypéronymes).
À partir des éléments extraits de la question, une recherche est lancée grâce à un moteur de recherche booléen qui permet les alternances proposées. La recherche est menée par paragraphe dans les documents. Les propositions du moteur de recherche sont en effet des paragraphes qui contiennent les entités les plus représentatives de la question et une entité correspondant au type de la question.
Enfin, les propositions du moteur de recherche sont soumises à l’analyseur probabiliste et un formulaire sémantique est construit. L’unification du formulaire de la question avec celui de la réponse est tenté, d’abord au niveau lexical, puis avec les alternances possibles. Lorsqu’une unification des formulaires est possible, la méthodologie cherche à décider si l’entité qui correspond au type de la question répond bien à cette question grâce à une représentation logique et une justification logique basées sur la connaissance du monde apportée par WordNet, ainsi qu’une résolution de coréférence au niveau du paragraphe considérée comme rare dans cette fenêtre. Cette partie logique de la méthodologie est peu détaillée et peu convaincante, peut-être à cause de la nature commerciale du système, dont nombre de spécificités et de fonctionnements restent confidentiels.