L’examen des résultats de l’évaluation va nous permettre d’identifier les points
forts et les faiblesses de notre méthode. La première démarche à envisager est
l’examen global de notre méthodologie, qui valide ou infirme l’utilité
d’un traitement basé sur des méthodes linguistiques dans le cadre de la
gestion de l’information. C’est d’abord dans la perspective de la tâche de
question-réponse que nous testons notre système. Pour ce faire, nous
confrontons les mesures de plancher avec les résultats de la méthode dite
« globale ».
Ce que nous appelons méthode globale est une application du système sur les
textes qui met en œuvre l’ensemble des processus et enrichissements disponibles
(analyse morpho-syntaxique, désambiguïsation sémantique, résolution de la
coréférence des pronoms sujets, synonymie, traits sémantiques, dérivation
morphologique). Au niveau des contraintes paramétrables, cette méthode
globale privilégie d’une part la précision en imposant la présence de
l’unité lexicale focus (cf. section 6.2.2 page ), mais sans négliger le
rappel, car la mise en correspondance des dépendances de la requête et des
réponses candidates ne rejette ces dernières que si aucune coïncidence n’est
constatée.
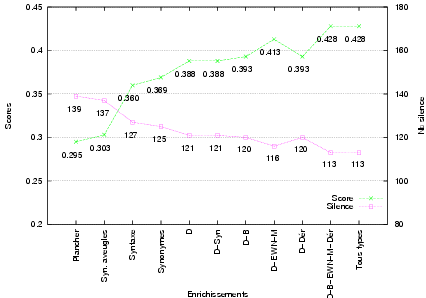
Le tableau 7.1 page indique clairement que notre méthode améliore non
seulement la qualité des réponses apportées en promouvant plus efficacement les
bonnes réponses (amélioration : 45%), mais augmente également son potentiel à
apporter une réponse à la question posée (amélioration : 19%). L’enrichissement
synonymique aveugle n’apporte que peu d’amélioration par rapport au plancher.
Toutefois, il est difficile de juger de ce résultat sans disposer des chiffres qui
évaluent un enrichissement, certes semblable à celui-ci, mais soumis à la sélection
de la désambiguïsation sémantique. Ce tableau ne permet pas non plus
d’identifier l’apport respectif des enrichissements qui nous ont conduit à ces
résultats.
|
|
|
|
|
| | Enrichissement | Score | Sans réponse |
|
|
|
|
|
| | Plancher | 0,295 | 139 |
|
|
| | Syn. aveugles | 0,303 | 137 |
|
|
|
|
|
| | Tous types | 0,428 | 113 |
|
|
|
|
|
| | |
| Tab. 7.1: | Résultats des planchers et de la méthode globale selon le
protocole de question-réponse. |
|
La table 7.2 page présente donc les résultats comparés des différents
modes d’enrichissement utilisés dans le cadre de la méthode globale. La
présentation du tableau montre un enrichissement croissant :
- le premier de ces enrichissements (Synonymie aveugle) a déjà été
présenté : il s’agit du plancher enrichi par les synonymes du Dubois
mais sans discernement. Aucune analyse n’a été apportée et aucune
résolution de coréférence n’a été réalisée. Le reste du tableau par
contre correspond à la méthode globale et la méthode de coréférence
a été utilisée ;
- la ligne Syntaxe présente les résultats de l’interrogation après analyse
morpho-syntaxique du texte. Les traits sémantiques sont ajoutés à ce
stade et les enrichissements suivants profitent de l’analyse syntaxique ;
- le champ Synonymes indique l’apport d’une synonymie aveugle
appliquée après analyse syntaxique des documents ;
- la ligne Dubois (D) indique un enrichissement réalisé à l’aide
des synonymes contextuels du dictionnaire Dubois suite à la
désambiguïsation sémantique. À partir de cette ligne, tous les
enrichissements bénéficient de cette désambiguïsation ;
- la ligne Dubois - Synonymes (D-Syn) met en œuvre
l’enrichissement contextualisé pour les synonymes du dictionnaire
Dubois, mais applique également un enrichissement aveugle des mots
qui n’ont pas été désambiguïsés à partir de ces mêmes synonymes
issus du Dubois ;
- la ligne Dubois - Bailly (D-B) présente les résultats dus à
l’enrichissement des synonymes contextuels conjoints des dictionnaires
Dubois et Bailly. Aucun enrichissement aveugle n’est effectué ;
- le champ Dubois - EuroWordNet - Memodata (D-EWN-M)
présente les résultats dus à l’enrichissement des synonymes contextuels
conjoints des dictionnaires Dubois, EuroWordNet et Memodata. Aucun
enrichissement aveugle n’est effectué ;
- la ligne Dubois - Dérivés (D-Dér) indique l’apport de la dérivation
morphologique couplée à l’enrichissement contextuel des synonymes
du dictionnaire Dubois. Aucun enrichissement aveugle n’est effectué ;
- le champ Dubois - Bailly - EuroWordNet - Memodata -
Dérivés (D-B-EWN-M-Dér) affiche les résultats de l’ensemble
des enrichissements possibles, exception faite de l’enrichissement
synonymique aveugle des unités lexicales qui n’ont pas été
désambiguïsées ;
- enfin, la ligne Tous types rassemble tous les modes d’enrichissement
issus de méthodes linguistiques. Les enrichissements de la ligne
précédente y sont effectués, auxquels est adjoint l’enrichissement
aveugle des unités lexicales non désambiguïsées.
|
|
|
|
|
| | Enrichissement | Score | Sans réponse |
|
|
|
|
|
| | Plancher | 0,295 | 139 |
|
|
| | Syn. aveugles | 0,303 | 137 |
|
|
|
|
|
| | Syntaxe | 0,360 | 127 |
|
|
| | Synonymes | 0,369 | 125 |
|
|
| | D | 0,388 | 121 |
|
|
| | D-Syn | 0,388 | 121 |
|
|
| | D-B | 0,393 | 120 |
|
|
| | D-EWN-M | 0,413 | 116 |
|
|
| | D-Dér | 0,393 | 120 |
|
|
| | D-B-EWN-M-Dér | 0,428 | 113 |
|
|
| | Tous types | 0,428 | 113 |
|
|
|
|
|
| | |
| Tab. 7.2: | Résultats des planchers et de la méthode globale selon le
protocole de question-réponse. |
|
L’examen de ces résultats confirme l’apport important des traitements
linguistiques, tant au niveau du score qu’à celui du nombre de réponses
apportées. On voit principalement l’intérêt de la synonymie ciblée (D) par
rapport à son équivalent aveugle (Synonymes). L’intérêt de la syntaxe seule n’est
pas évident. Il pourrait être montré s’il ressort que cet apport n’est pas
uniquement issu de la résolution de la coréférence (cf. table 7.3 page ).
Toutefois, l’analyse syntaxique n’est utilisée ici que comme support à d’autres
enrichissements. Par exemple, il est évident que l’enrichissement synonymique
contextuel est plus efficace si une analyse syntaxique est effectuée (Synonymes)
que lorsque ce type d’enrichissement est effectué sur les simples mots-clefs
extraits d’une requête (Syn. aveugles). Trois autres points intéressants ressortent
de ces résultats.
Tout d’abord, nous constatons le faible apport de l’enrichissement
issu de la dérivation morphologique (D-Dér). L’analyse des questions à
laquelle nous avons procédé lors de la constitution de l’ensemble des
requêtes à utiliser dans le protocole d’évaluation nous a permis de déceler
une particularité qui est peut-être à l’origine de cet insuccès. En effet,
les verbes dans les énoncés des requêtes correspondent fréquemment
à des dérivation de noms ou d’adjectifs, présents dans plusieurs cas à
l’intérieur de leurs réponses. Nous avons suffisamment signalé la richesse de
l’information liée aux verbes par rapport à celle rattachée aux autres catégorie
grammaticale dans le dictionnaire Dubois, à l’origine de l’enrichissement
dérivationnel. Or il est fréquent que des dérivations mentionnées au
départ d’entrées verbales ne rencontrent pas leur pendant à partir d’une
autre catégorie grammaticale vers un dérivé verbal. Par exemple, alors
qu’un lien de dérivation existe entre protéger et protecteur au départ du
verbe, aucun lien équivalent n’est indiqué au départ de protecteur vers
protéger. Du fait de cette carence, particulièrement sensible pour les
noms et les adjectifs, de nombreux enrichissements ne peuvent s’effectuer.
De ce fait, il arrive que des réponses ne soient pas sélectionnées lors de
l’interrogation.
A contrario, nous remarquons la bonne tenue de l’information des
dictionnaires sémantiques (EuroWordNet et Memodata), surtout par rapport à
l’enrichissement apporté par le dictionnaire Bailly. Nous avions, il est vrai,
souligné le peu d’intérêt de l’information de ce dictionnaire lorsque nous l’avons
passé en revue (cf. section 3.4.2 page ). Malgré cette faiblesse du dictionnaire
Bailly, l’impact des synonymes contextuels sur la qualité des résultats est
parfaitement évidente. Les courbes présentées dans la figure 7.1 page précédente
permettent de confirmer de manière plus visuelle l’intérêt d’une analyse
linguistique et l’apport essentiel d’une bonne synonymie contextuelle. Enfin,
l’addition de synonymes aveugles sur les lexèmes non désambiguïsés
ne semble étrangement pas apporter la moindre amélioration. En effet,
l’adjonction de ces synonymes aveugles à l’enrichissement synonymique du
Dubois, comme à l’ensemble des autres enrichissements, n’améliore en rien
les performances du système. Toutefois, nous n’avons pu effectuer cet
enrichissement aveugle qu’à l’aide de l’information synonymique propre au
Dubois, à l’exclusion des autres dictionnaires dans lesquels nous puisons
l’information synonymique. Cet enrichissement peut être de piètre qualité,
surtout dans les catégories non verbales. Cela peut justifier la stagnation
constatée.
Les conclusions sur les différents types d’enrichissement que nous avons tirées
des précédents résultats doivent à présent être vérifiées. Validées ou invalidées
sur la méthode globale, ces techniques doivent à présent être soumises à des
variations de paramètres pour en constater les fluctuations. Pour ce faire, nous
avons d’abord neutralisé le module de résolution de coréférence, ce qui va nous
permettre de vérifier également l’importance de cet outil dans le processus de
structuration de l’information.
|
|
|
|
|
|
|
|
|
| | | Sans coréférence | Avec coréférence
|
|
|
|
|
| | Enrichissement | Score | Sans réponse | Score | Sans réponse |
|
|
|
|
|
|
|
|
|
| | Plancher | 0,295 | 139 | — | — |
|
|
|
|
| | Syn. aveugles | 0,303 | 137 | — | — |
|
|
|
|
|
|
|
|
|
| | Syntaxe | 0,275 | 144 | 0,360 | 127 |
|
|
|
|
| | Synonymes | 0,284 | 142 | 0,369 | 125 |
|
|
|
|
| | D | 0,304 | 138 | 0,388 | 121 |
|
|
|
|
| | D-Syn | 0,304 | 138 | 0,388 | 121 |
|
|
|
|
| | D-B | 0,303 | 138 | 0,393 | 120 |
|
|
|
|
| | D-EWN-M | 0,324 | 134 | 0,413 | 116 |
|
|
|
|
| | D-Dér | 0,304 | 138 | 0,393 | 120 |
|
|
|
|
| | D-B-EWN-M-Dér | 0,328 | 133 | 0,428 | 113 |
|
|
|
|
| | Tous types | 0,328 | 133 | 0,428 | 113 |
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.3: | Résultats comparés de la méthode globale avec et sans
coréférence. |
|
Le tableau 7.3 page précédente présente les différents résultats issus des
divers enrichissements, mais privés de la résolution de la coréférence. En
comparant les résultats de l’interrogation de la méthode globale avec et sans
coréférence, on peut constater l’ampleur de l’impact de cette coréférence sur
l’efficacité du système : pour chacun des enrichissements, la perte de qualité est
de plus de 0,075 point (soit près de 25%) et le nombre de questions qui
n’obtiennent pas de réponse croît d’approximativement 20 unités (presque 20%).
L’intérêt de l’utilisation d’un module de coréférence, même aussi rudimentaire
que la technique que nous avons utilisée, est clairement établi. Nous traiterons
ultérieurement de l’extension de cette coréférence aux adjectifs possessifs et aux
autres pronoms.
Nous déduisons de ce tableau que l’apport d’une simple analyse
morpho-syntaxique ne bénéficie pas à la tâche de question-réponse. Toutefois, le
nombre de questions qui ont obtenu une réponse uniquement par la syntaxe est
de 56, ce qui donne un score maximal de 0,280. Le score de 0,275 obtenu est donc
presque parfait, proportionnellement plus élevé que celui du plancher, pourtant déjà
excellent, de 0,295 pour un maximum de 0,305. Nous verrons dans les mesures
traditionnelles
l’impact de la syntaxe sur la précision (cf. section 7.3.2 page ). L’examen des
différentes valeurs présentées dans ce tableau ne montre pas de variation
particulière d’un type d’enrichissement par rapport aux autres dans une
proportion réellement différente de celles de la méthode globale. Ce statu
quo nous conforte donc dans nos observations concernant les différents
enrichissements : importance de l’enrichissement synonymique contextuel,
faiblesse relative de la dérivation morphologique pour ce type de questions et peu
d’intérêt de l’enrichissement aveugle des lexèmes non désambiguïsés.
Toutefois, il est possible que l’exploitation ou non de la coréférence des
pronoms sujets ne soit pas de nature à révéler les variations dans les possibilités
des différents types d’enrichissements. Il est donc important d’étudier le
comportement de ces enrichissements dans des situations différentes afin de
pouvoir juger de leur apport réel. À partir de textes tantôt soumis à la
résolution de la coréférence et tantôt non, nous allons faire varier les
paramètres liés à la mise en correspondance des questions et réponses
(utilisation ou non de l’unité lexicale focus, utilisation et variation du seuil de
correspondance des dépendances contenues dans les réponses candidates et dans
les questions).
Le système appliqué sur les textes avec résolution de la coréférence présente
les meilleurs résultats si les réponses candidates qui ne présentent pas de
correspondance de dépendance avec la question ne sont pas rejetées. Ils sont
également les meilleurs dans le cas où la coréférence n’est pas résolue. Ces
résultats apparaissent dans la table 7.4 page .
|
|
|
|
|
|
|
|
|
| | | Avec coréférence | Sans coréférence
|
|
|
|
|
| | Enrichissement | Score | Sans réponse | Score | Sans réponse |
|
|
|
|
|
|
|
|
|
| | Syntaxe | 0,365 | 126 | 0,280 | 143 |
|
|
|
|
| | Synonymes | 0,379 | 123 | 0,289 | 141 |
|
|
|
|
| | D | 0,398 | 119 | 0,309 | 137 |
|
|
|
|
| | D-Syn | 0,398 | 119 | 0,309 | 137 |
|
|
|
|
| | D-B | 0,403 | 118 | 0,308 | 137 |
|
|
|
|
| | D-EWN-M | 0,423 | 114 | 0,329 | 133 |
|
|
|
|
| | D-Dér | 0,403 | 118 | 0,309 | 137 |
|
|
|
|
| | D-B-EWN-M-Dér | 0,438 | 111 | 0,333 | 132 |
|
|
|
|
| | Tous types | 0,438 | 111 | 0,333 | 132 |
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.4: | Interrogation sans rejet des réponses sans correspondance
syntaxique avec la question : résultats avec et sans coréférence. |
|
Nous observons que dans ce cas également, les constatations que
nous avons faites sur l’apport respectif des différents enrichissements
restent d’actualité, que cet enrichissement soit synonymique contextuel ou
aveugle, dérivationnel ou qu’il provienne de la résolution de la coréférence.
Les résultats présentés par les textes avec coréférence en particulier
comptent parmi les meilleurs que nous avons obtenus. Près de la moitié des
questions obtiennent une réponse dans les cinq premières propositions, et les
résultats présentés quel que soit l’enrichissement sont supérieurs à tous les
autres.
Nous relevons particulièrement la réaction inattendue du système à la
demande de correspondance exacte des dépendances syntaxiques. En effet, les
résultats sont meilleurs lorsque la contrainte syntaxique diminue. Pour évaluer
l’impact des contraintes syntaxiques sur les résultats, nous présentons dans le
tableau 7.5 page les résultats de la méthode globale, mais nous faisons varier
le seuil du rejet des réponses qui ne concordent pas totalement avec la question.
Les résultats pour un seuil de 10%, identiques à ceux du seuil à 0%, n’ont pas
été présentés, de même que ceux de 30%, identiques aux résultats du seuil à
20%.
|
|
|
|
|
|
|
|
|
|
|
|
|
| | | Seuil = 0% | Seuil = 20% | Seuil = 40%
|
|
|
|
|
|
|
| | Enrichissement | Score | Sans rép. | Score | Sans rép. | Score | Sans rép. |
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Syntaxe | 0,360 | 127 | 0,355 | 128 | 0,335 | 132 |
|
|
|
|
|
|
| | Synonymes | 0,369 | 125 | 0,364 | 126 | 0,344 | 130 |
|
|
|
|
|
|
| | D | 0,388 | 121 | 0,378 | 123 | 0,358 | 127 |
|
|
|
|
|
|
| | D-Syn | 0,388 | 121 | 0,378 | 123 | 0,358 | 127 |
|
|
|
|
|
|
| | D-B | 0,393 | 120 | 0,383 | 122 | 0,363 | 126 |
|
|
|
|
|
|
| | D-EWN-M | 0,413 | 116 | 0,403 | 118 | 0,378 | 123 |
|
|
|
|
|
|
| | D-Dér | 0,393 | 120 | 0,383 | 122 | 0,363 | 126 |
|
|
|
|
|
|
| | D-B-EWN-M-Dér | 0,428 | 113 | 0,418 | 115 | 0,388 | 121 |
|
|
|
|
|
|
| | Tous types | 0,428 | 113 | 0,418 | 115 | 0,388 | 121 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.5: | Résultats de la méthode globale avec variation du taux minimal
de concordance entre question et réponse. |
|
Ces résultats montrent que l’impact de l’élévation du seuil de concordance
des dépendances sur les performances du système est plutôt négatif, même si
cette variation n’a pas d’impact entre 0% et 20%, ni entre 20% et 40%. La
diminution de qualité des réponses lors de l’augmentation des contraintes sur la
syntaxe est surprenante, mais elle peut être justifiée. En effet, le renforcement
d’une contrainte implique généralement la diminution des propositions de
réponses. À partir de ce fait, la détérioration des résultats s’explique par la
conjonction de deux facteurs : une réponse dont les dépendances ne
correspondent pas à celles de la question est normalement placée très bas
dans la liste des propositions, et ne donnera lieu à un résultat que si
aucune réponse correcte n’est placée plus haut, mais ne fera pas évoluer
favorablement le score si elle est rejetée ; d’autre part, une dépendance
syntaxique présente dans une question propose un schéma très strict
qui peut ne s’adapter que partiellement à la réalité du document qui y
correspond.
De fait, la rigueur de ce schéma peut poser un problème dans le cadre
d’énoncés où une dépendance sémantique de même type unit les deux mêmes
entités, mais que ce lien n’existe au niveau syntaxique que de manière indirecte.
Par exemple dans l’énoncé
Julius Caesar était le neveu de l’empereur Tibère.
extrait de l’Encyclopédie Hachette Multimédia, aucune dépendance ne permet de
relier directement neveu et Tibère. En effet, le rattachement prépositionnel
unit neveu et empereur (NARG[INDIR](neveu,de,empereur)), tandis
que le mot empereur est lui-même relié à Tibère en tant qu’apposition
du nom (NN(empereur,Tibère)). Une solution pour régler ce type de
problème serait de considérer des dépendances indirectes permettant
de définir un même lien sémantique comme correspondant à celles de
la requête, même si cette correspondance est effectuée à un moindre
degré.
Un autre cas où la rigueur du schéma syntaxique peut poser un problème à la
mise en correspondance de la question et de la réponse vient de lacunes dans
l’analyse syntaxique fournie par la grammaire. De fait, si nous prenons une
phrase comme
Marc Antoine fut l’ami et le second de César.
extraite de l’Encyclopédie Hachette Multimédia, l’analyse syntaxique de XIP ne
comportera qu’un seul rattachement prépositionnel impliquant César :
NMOD[INDIR](second,de,César). Une dépendance prépositionnelle impliquant
ami et César dans une question ne pourrait donc être mise en correspondance
avec la phrase présentée.
Dans ces deux cas, l’information lexicale est présente ainsi que l’information
syntaxique. Le problème vient de ce que ces deux informations ne sont pas
forcément compatibles avec celles des questions proposées, dont la syntaxe est
souvent plus simple, et ne comporte donc généralement ni lacune ni de relation
indirecte.
L’absence de l’unité lexicale correspondant au focus est le dernier
paramètre sur lequel nous pouvons agir pour améliorer certains aspects
des résultats produits par le système. Le tableau 7.6 page présente
les différents résultats obtenus en retirant le lexème porteur du focus
des exigences de la question et en faisant varier les contraintes sur le
seuil de concordance des dépendances des réponses et de la question :
aucune exigence, suppression des concordances nulles, seuil de 10% à
40%.
|
|
|
|
|
| | Seuil | Score | Sans réponse |
|
|
|
|
|
| | Sans seuil | 0,504 | 97 |
|
|
| | 0% | 0,489 | 100 |
|
|
| | 10% | 0,484 | 101 |
|
|
| | 20% | 0,448 | 109 |
|
|
| | 30% | 0,433 | 112 |
|
|
| | 40% | 0,403 | 118 |
|
|
|
|
|
| | |
| Tab. 7.6: | Résultats de la méthode sans focus avec variation du taux
minimal de concordance entre question et réponse. |
|
De ces résultats, nous pouvons déduire que les réponses à concordance basse
(sous 20%) n’influencent que faiblement la qualité des résultats. Les
courbes de résultats (cf. figure 7.2 page précédente) permettent de
mieux percevoir l’impact des variations du seuil sur les performances. Des
intervalles relativement importants entre les taux qui modifient réellement les
résultats proviennent probablement de ce que la plupart des questions sont
courtes, et comportent donc peu de dépendances. Les variations de taux de
correspondances sont peu nombreuses entre 0% et 20% et entre 20%
et 40% lorsque peu de dépendances sont mises en jeu. Il est donc plus
courant d’obtenir des taux de correspondance nuls ou échelonnés de 20% en
20%.
Il est cependant paradoxal de constater que les scores sont supérieurs
lorsque les contraintes sont diminuées, tant par la suppression du
focus
que par la diminution des contraintes syntaxiques sous la forme d’un seuil bas ou
inexistant. Toutefois, l’augmentation du nombre des propositions de réponses
alliée à une classification des réponses où les contraintes syntaxiques ont la
prépondérance peut expliquer ce comportement inattendu.
Il serait intéressant de pouvoir tester le même système en le modifiant de
manière à ce que la ou les dépendances qui comportent le focus soient
obligatoirement retrouvées dans les réponses candidates, surtout dans les cas où
l’unité lexicale désignée par le focus n’est pas exigée.
De plus, pour l’ensemble des derniers résultats présentés, le détail des
enrichissements nous permet de confirmer les conclusions que nous tirions
à propos de leur intérêt respectif. En particulier, nous constatons le
peu d’efficacité de la morphologie dérivationnelle et de l’enrichissement
aveugle des lexèmes non désambiguïsés, tandis que l’importance de la
coréférence est confirmée. Dans tous les cas, l’apport d’un enrichissement
contextuel lié au sens est également un atout majeur. Par ailleurs, la
classification des réponses liée à la syntaxe semble un moyen efficace
de conserver de fait certaines contraintes syntaxiques sur les réponses
proposées.
Les critères d’évaluation intéressants pour les autres disciplines liées à la gestion
de l’information ne sont pas forcément identiques à ceux qui servent à évaluer la
tâche de question-réponse. En particulier, toutes les réponses possibles y sont
généralement prises en compte : rappel, ainsi que toutes les réponses fournies :
précision (cf. section 1.2.1 page ). Le corpus que nous traitons comporte
249 réponses correctes pour les 200 questions qui lui sont proposées.
Malgré ces différences, les paramètres que nous pouvons faire varier sont
identiques à ceux que nous avons manipulés pour évaluer les capacités de
question-réponse du système, excepté la possibilité de travailler sur des fenêtres
plus larges (paragraphe ou texte). Les conclusions que nous pouvons tirer sont
souvent semblables. Nous nous attardons donc peu sur les phénomènes déjà
constatés, tandis que nous insistons sur les particularités propres à ce type de
calcul.
La méthode globale permet d’isoler les résultats présentés dans le
tableau 7.7 page . Nous constatons immédiatement que la précision atteinte
par le plancher est excellente, mais que ce résultat est tempéré par un rappel
bas. Le calcul de la F-mesure permet de ne pas s’y tromper. En effet, alors que
cette F-mesure est honorable lorsque la précision est favorisée (β=0,5), elle
s’effondre de près de 20 points dès lors qu’il y a équivalence entre la précision et
le rappel (β=1), et chute encore si le rappel est privilégié (β=2). La méthode
globale n’atteint pas le même niveau de précision, bien que cette précision soit de
plus de 38% et qu’elle permette d’obtenir une mesure d’ensemble supérieure
dans tous les cas à la mesure du plancher, même lorsque la précision est
favorisée.
|
|
|
|
|
|
|
|
|
|
|
| | Enrichissement | Précision | Rappel | F-m1 | F-m2 | F-m3 |
|
|
|
|
|
|
|
|
|
|
|
| | Plancher | 83.75% | 26.91% | 58.88 | 40.73 | 31.13 |
|
|
|
|
|
| | Syn. aveugles | 80.90% | 28.92% | 59.50 | 42.60 | 33.18 |
|
|
|
|
|
|
|
|
|
|
|
| | Tous types | 79.83% | 38.15% | 65.52 | 51.63 | 42.60 |
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.7: | Résultats traditionnels des méthodes de plancher et de la
méthode globale. |
|
Le tableau quantitatif 7.8 page et les courbes d’évaluation de la
figure 7.3 page permettent de confirmer ces chiffres : le nombre de
bonnes réponses apportées par notre méthode dépasse le plancher de plus
de 41%, et le nombre de questions qui obtiennent au moins une bonne
réponse augmente de plus de 40%. Il est vrai que notre méthode double le
nombre de réponses fausses avec 24 cas là où la mesure de plancher n’en
a que 13. Cette différence justifie en partie la différence de précision
entre le plancher et notre méthode globale. Les réponses rejetées (Rejet)
sont les candidates dont le taux de concordance des dépendances avec
celles de la question est inférieur au seuil prescrit (ici 0%). Parmi ces
réponses rejetées, nous indiquons le nombre de propositions correctes (Rej.
exact).
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Enrichissement | Exact | 1 exact | Faux | Sans | Rejet | Rej. exact |
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Plancher | 67 | 59 | 13 | 136 | — | — |
|
|
|
|
|
|
| | Syn. aveugles | 72 | 61 | 17 | 133 | — | — |
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Tous types | 95 | 83 | 24 | 109 | 13 | 3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.8: | Résultats quantitatifs traditionnels de la méthode de plancher
et de la méthode globale. |
|
Les caractéristiques du corpus d’évaluation, choisi délibérément parmi des
articles encyclopédiques traitant de personnages pour les raisons déjà évoquées,
sont à l’origine de la qualité des réponses de la méthode de plancher qui
est particulièrement élevée, et peut-être, dans une mesure que nous
espérons moindre, des autres résultats également. Ce corpus contient en
effet une grande quantité de noms propres, ce qui est fréquent dans une
encyclopédie, plus encore si les documents portent sur des personnes. Comme
une grande majorité des questions contient au moins un nom propre
(93%), la tâche de recherche d’information par mots-clefs s’en trouve
facilitée .
Les résultats obtenus dans cette évaluation ne seront donc pas forcément
représentatifs de la qualité des méthodes sur d’autres types de textes ou de
sujets. Toutefois, les processus mis en œuvre dans notre méthode peuvent être
testés les uns par rapport aux autres et nous avons donc la possibilité de
déterminer leurs intérêts respectifs. Par ailleurs, notre méthode est destinée
à une utilisation généraliste, et ne doit donc pas récuser un type de
texte particulier, qu’il lui soit favorable ou défavorable, comme c’est ici le
cas.
La présentation des résultats de la méthode globale détaillés en fonction du
processus d’enrichissement dans le tableau 7.9 page permet de confirmer
certaines conclusions que nous avons tirées lors de l’analyse des données obtenues
dans la perspective de la tâche de question-réponse.
Tout d’abord, nous constatons ici l’apport de l’analyse morpho-syntaxique en
comparaison avec les résultats du plancher. Le bénéfice est manifeste du point de
vue de la précision, comme nous l’avions pressenti sans pouvoir le démontrer
dans les chiffres issus de la tâche de question-réponse. L’augmentation du rappel
est due à l’utilisation de la coréférence, mais ce type d’enrichissement ne
privilégie pas la précision. Le tableau quantitatif (cf. table 7.10 page ) des
mêmes résultats confirme la qualité de l’information identifiée au travers de
cette seule analyse, qui voit augmenter significativement le nombre de ses
bonnes réponses grâce à la résolution anaphorique sans accroître en
proportion le nombre des erreurs. L’analyse des résultats sans application
de la coréférence (cf. table 7.11 page ) ne se démarque pas de cette
observation.
|
|
|
|
|
|
|
|
|
|
|
| | Enrichissement | Précision | Rappel | F-m1 | F-m2 | F-m3 |
|
|
|
|
|
|
|
|
|
|
|
| | Plancher | 83.75% | 26.91% | 58.88 | 40.73 | 31.13 |
|
|
|
|
|
| | Syn. aveugles | 80.90% | 28.92% | 59.50 | 42.60 | 33.18 |
|
|
|
|
|
|
|
|
|
|
|
| | Syntaxe | 84.78% | 31.33% | 63.21 | 45.75 | 35.85 |
|
|
|
|
|
| | Synonymes | 83.67% | 32.93% | 63.96 | 47.26 | 37.48 |
|
|
|
|
|
| | D | 81.73% | 34.14% | 63.91 | 48.16 | 38.64 |
|
|
|
|
|
| | D-Syn | 81.13% | 34.54% | 63.89 | 48.45 | 39.02 |
|
|
|
|
|
| | D-B | 78.38% | 34.94% | 62.77 | 48.33 | 39.30 |
|
|
|
|
|
| | D-EWN-M | 81.82% | 36.14% | 65.31 | 50.14 | 40.69 |
|
|
|
|
|
| | D-Dér | 82.08% | 34.94% | 64.64 | 49.01 | 39.47 |
|
|
|
|
|
| | D-B-EWN-M-Dér | 79.66% | 37.75% | 65.19 | 51.23 | 42.19 |
|
|
|
|
|
| | Tous types | 79.83% | 38.15% | 65.52 | 51.63 | 42.60 |
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.9: | Résultats traditionnels détaillés des planchers et de la méthode
globale. |
|
La faiblesse de deux enrichissements est également confirmée par ces
résultats, tant par les mesures de précision et de rappel que par les mesures
quantifiées. Il s’agit des apports de la synonymie aveugle et de la morphologie
dérivationnelle. Les apports de la synonymie aux lexèmes qui n’ont pas été
désambiguïsés sont anecdotiques : en précision comme en rappel, elle est
de 1% et l’amélioration quantitative n’est pas plus convaincante. La
dérivation morphologique est tout aussi décevante, qu’elle soit appliquée
après la seule désambiguïsation ou après l’adjonction de tous les autres
enrichissements. Ces enrichissements ne sont donc pas très significatifs dans notre
méthode.
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Enrichissement | Exact | 1 exact | Faux | Sans | Rejet | Rej. exact |
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Plancher | 67 | 59 | 13 | 136 | 0 | 0 |
|
|
|
|
|
|
| | Syn. aveugles | 72 | 61 | 17 | 133 | 0 | 0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Syntaxe | 78 | 70 | 14 | 124 | 5 | 1 |
|
|
|
|
|
|
| | Synonymes | 82 | 72 | 16 | 122 | 9 | 2 |
|
|
|
|
|
|
| | D | 85 | 76 | 19 | 118 | 11 | 3 |
|
|
|
|
|
|
| | D-Syn | 86 | 76 | 20 | 118 | 11 | 3 |
|
|
|
|
|
|
| | D-B | 87 | 77 | 24 | 115 | 12 | 3 |
|
|
|
|
|
|
| | D-EWN-M | 90 | 81 | 20 | 113 | 11 | 3 |
|
|
|
|
|
|
| | D-Dér | 87 | 77 | 19 | 117 | 11 | 3 |
|
|
|
|
|
|
| | D-B-EWN-M-Dér | 94 | 83 | 24 | 109 | 12 | 3 |
|
|
|
|
|
|
| | Tous types | 95 | 83 | 24 | 109 | 13 | 3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.10: | Résultats traditionnels quantitatifs détaillés du plancher et de
la méthode globale. |
|
Par contre, nous constatons les bons résultats obtenus par l’enrichissement
synonymique contextuel en général, avec une meilleure efficacité pour les
dictionnaires sémantiques (EuroWordNet et Memodata) que pour le dictionnaire
synonymique (Bailly). Le tableau des mesures quantitatives permet d’envisager
que les bonnes réponses dont l’obtention est permise par les synonymes issus du
Bailly (deux de plus que l’enrichissement du seul Dubois), par les dictionnaires
sémantiques (cinq de plus que l’enrichissement du Dubois) et par la dérivation
morphologique (deux de plus que l’enrichissement du Dubois) ne se recouvrent
pas. Nous constatons aussi que, si la dérivation morphologique n’offre somme
toute qu’un apport modeste au système, sa contribution n’en est pas moins
d’excellente qualité, car aucune erreur n’est générée par cet enrichissement.
Chacun de ces enrichissements a donc sa raison d’être utilisé dans notre
méthodologie.
Les chiffres des tableaux 7.11 page et 7.12 page présentent les résultats
de l’interrogation de la base en exploitant les mêmes processus – excepté la
technique de résolution de coréférence des pronoms sujets – et les mêmes
paramètres, à savoir la présence de l’unité lexicale désignée par le focus dans la
réponse ainsi que l’élimination des réponses qui ne présentent aucune
dépendance concordante avec la requête. Ces résultats permettent de confirmer
l’importance de l’analyse syntaxique, qui conserve un avantage sur les résultats
du plancher grâce à une précision meilleure tandis que la perte en rappel reste
relativement faible.
L’analyse quantitative surtout permet de constater l’amélioration apportée
par la syntaxe (diminution des réponses fausses de 31% pour une diminution de
12% des réponses fournies). L’examen des autres résultats permet de légitimer
nos appréciations des autres enrichissements les uns par rapport aux
autres et de constater que les réponses apportées par l’enrichissement
synonymique issu des différents types de dictionnaires ne se recoupent
pas.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | | Sans coréférence | Avec coréférence
| | Enrichissement | Précision | Rappel | F-m1 | F-m2 | F-m3 | Précision | Rappel | F-m1 | F-m2 | F-m3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Syntaxe | 86.76% | 23.69% | 56.62 | 37.22 | 27.73 | 84.78% | 31.33% | 63.21 | 45.75 | 35.85 |
|
|
|
|
|
|
|
|
|
|
| | Synonymes | 85.14% | 25.30% | 57.80 | 39.01 | 29.44 | 83.67% | 32.93% | 63.96 | 47.26 | 37.48 |
|
|
|
|
|
|
|
|
|
|
| | D | 82.28% | 26.10% | 57.52 | 39.63 | 30.23 | 81.73% | 34.14% | 63.91 | 48.16 | 38.64 |
|
|
|
|
|
|
|
|
|
|
| | D-Syn | 81.48% | 26.51% | 57.59 | 40.00 | 30.64 | 81.13% | 34.54% | 63.89 | 48.45 | 39.02 |
|
|
|
|
|
|
|
|
|
|
| | D-B | 78.57% | 26.51% | 56.41 | 39.64 | 30.56 | 78.38% | 34.94% | 62.77 | 48.33 | 39.30 |
|
|
|
|
|
|
|
|
|
|
| | D-EWN-M | 81.18% | 27.71% | 58.57 | 41.32 | 31.91 | 81.82% | 36.14% | 65.31 | 50.14 | 40.69 |
|
|
|
|
|
|
|
|
|
|
| | D-Dér | 82.28% | 26.10% | 57.52 | 39.63 | 30.23 | 82.08% | 34.94% | 64.64 | 49.01 | 39.47 |
|
|
|
|
|
|
|
|
|
|
| | D-B-EWN-M-Dér | 76.92% | 28.11% | 57.10 | 41.18 | 32.20 | 79.66% | 37.75% | 65.19 | 51.23 | 42.19 |
|
|
|
|
|
|
|
|
|
|
| | Tous types | 78.02% | 28.51% | 57.91 | 41.76 | 32.66 | 79.83% | 38.15% | 65.52 | 51.63 | 42.60 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.11: | Résultats traditionnels comparés de l’utilisation ou non de la
résolution de la coréférence dans la méthode globale. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | | Sans coréférence | Avec coréférence
| | Enrichissement | Exact | 1 ex. | Faux | Sans | Rejet | R. ex. | Exact | 1 ex. | Faux | Sans | Rejet | R. ex. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Syntaxe | 59 | 53 | 9 | 142 | 5 | 1 | 78 | 70 | 14 | 124 | 5 | 1 |
|
|
|
|
|
|
|
|
|
|
|
|
| | Synonymes | 63 | 55 | 11 | 139 | 7 | 2 | 82 | 72 | 16 | 122 | 9 | 2 |
|
|
|
|
|
|
|
|
|
|
|
|
| | D | 65 | 58 | 14 | 135 | 9 | 3 | 85 | 76 | 19 | 118 | 11 | 3 |
|
|
|
|
|
|
|
|
|
|
|
|
| | D-Syn | 66 | 58 | 15 | 134 | 9 | 3 | 86 | 76 | 20 | 118 | 11 | 3 |
|
|
|
|
|
|
|
|
|
|
|
|
| | D-B | 66 | 59 | 18 | 133 | 10 | 3 | 87 | 77 | 24 | 115 | 12 | 3 |
|
|
|
|
|
|
|
|
|
|
|
|
| | D-EWN-M | 69 | 62 | 16 | 130 | 9 | 3 | 90 | 81 | 20 | 113 | 11 | 3 |
|
|
|
|
|
|
|
|
|
|
|
|
| | D-Dér | 65 | 58 | 14 | 135 | 9 | 3 | 87 | 77 | 19 | 117 | 11 | 3 |
|
|
|
|
|
|
|
|
|
|
|
|
| | D-B-EWN-M-Dér | 70 | 63 | 21 | 127 | 10 | 3 | 94 | 83 | 24 | 109 | 12 | 3 |
|
|
|
|
|
|
|
|
|
|
|
|
| | Tous types | 71 | 63 | 20 | 128 | 10 | 3 | 95 | 83 | 24 | 109 | 13 | 3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.12: | Résultats quantitatifs traditionnels comparés de l’utilisation ou
non de la résolution de la coréférence dans la méthode globale. |
|
Nous pouvons à présent manipuler le seuil de concordance des dépendances
des questions et des réponses, à partir duquel une phrase peut être acceptée
comme réponse à la question posée. Le seuil testé précédemment était de 0%,
c’est-à-dire que la réponse était supprimée dès qu’aucune dépendance ne
correspondait parfaitement entre la question et la réponse. Les tableaux 7.13
page et 7.14 page comparent les résultats obtenus lors de l’interrogation
avec rejet des réponses sans concordance de dépendance avec la question, et ceux
obtenus sans rejet. Contrairement au cas de figure obtenu lors de l’évaluation en
question-réponse, les résultats obtenus en supprimant le seuil d’élimination de
réponses non concordantes ne produisent pas un grand changement dans les
résultats.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | | Sans seuil | Avec seuil à 0%
| | Enrichissement | Précision | Rappel | F-m1 | F-m2 | F-m3 | Précision | Rappel | F-m1 | F-m2 | F-m3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Syntaxe | 83.51% | 32.53% | 63.58 | 46.82 | 37.05 | 84.78% | 31.33% | 63.21 | 45.75 | 35.85 |
|
|
|
|
|
|
|
|
|
|
| | Synonymes | 81.31% | 34.94% | 64.25 | 48.88 | 39.44 | 83.67% | 32.93% | 63.96 | 47.26 | 37.48 |
|
|
|
|
|
|
|
|
|
|
| | D | 78.26% | 36.14% | 63.47 | 49.45 | 40.50 | 81.73% | 34.14% | 63.91 | 48.16 | 38.64 |
|
|
|
|
|
|
|
|
|
|
| | D-Syn | 77.78% | 36.55% | 63.46 | 49.73 | 40.88 | 81.13% | 34.54% | 63.89 | 48.45 | 39.02 |
|
|
|
|
|
|
|
|
|
|
| | D-B | 74.80% | 36.95% | 62.08 | 49.46 | 41.11 | 78.38% | 34.94% | 62.77 | 48.33 | 39.30 |
|
|
|
|
|
|
|
|
|
|
| | D-EWN-M | 78.51% | 38.15% | 64.80 | 51.35 | 42.52 | 81.82% | 36.14% | 65.31 | 50.14 | 40.69 |
|
|
|
|
|
|
|
|
|
|
| | D-Dér | 78.63% | 36.95% | 64.16 | 50.27 | 41.33 | 82.08% | 34.94% | 64.64 | 49.01 | 39.47 |
|
|
|
|
|
|
|
|
|
|
| | D-B-EWN-M-Dér | 76.15% | 39.76% | 64.37 | 52.24 | 43.96 | 79.66% | 37.75% | 65.19 | 51.23 | 42.19 |
|
|
|
|
|
|
|
|
|
|
| | Tous types | 75.76% | 40.16% | 64.35 | 52.49 | 44.33 | 79.83% | 38.15% | 65.52 | 51.63 | 42.60 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.13: | Résultats traditionnels comparés de l’utilisation d’un seuil de
rejet des réponses sans concordance syntaxique avec la question nul ou
minimal. |
|
Comme on pouvait le prévoir en diminuant les contraintes, la précision y perd
un peu et le rappel y gagne, mais le calcul de ces deux mesures confondues
(F-mesure avec β=1) donne globalement un résultat semblable. Cette différence
avec les résultats de question-réponse vient de l’élimination naturelle d’un grand
nombre de réponses à faible taux de concordance du fait de la classification des
réponses les plus pertinentes de l’élimination des réponses les moins susceptibles
d’être exactes dans la tâche de question-réponse. L’analyse des résultats
quantifiés confirme ce raisonnement : les réponses correctes sont un peu plus
nombreuses et les erreurs également.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | | Sans seuil | Avec seuil à 0%
| | Enrichissement | Exact | 1 exact | Faux | Sans | Exact | 1 exact | Faux | Sans | Rejet | Rej. exact |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Syntaxe | 81 | 72 | 16 | 122 | 78 | 70 | 14 | 124 | 5 | 1 |
|
|
|
|
|
|
|
|
|
|
| | Synonymes | 87 | 75 | 20 | 119 | 82 | 72 | 16 | 122 | 9 | 2 |
|
|
|
|
|
|
|
|
|
|
| | D | 90 | 79 | 25 | 115 | 85 | 76 | 19 | 118 | 11 | 3 |
|
|
|
|
|
|
|
|
|
|
| | D-Syn | 91 | 79 | 26 | 115 | 86 | 76 | 20 | 118 | 11 | 3 |
|
|
|
|
|
|
|
|
|
|
| | D-B | 92 | 80 | 31 | 112 | 87 | 77 | 24 | 115 | 12 | 3 |
|
|
|
|
|
|
|
|
|
|
| | D-EWN-M | 95 | 84 | 26 | 110 | 90 | 81 | 20 | 113 | 11 | 3 |
|
|
|
|
|
|
|
|
|
|
| | D-Dér | 92 | 80 | 25 | 114 | 87 | 77 | 19 | 117 | 11 | 3 |
|
|
|
|
|
|
|
|
|
|
| | D-B-EWN-M-Dér | 99 | 86 | 31 | 106 | 94 | 83 | 24 | 109 | 12 | 3 |
|
|
|
|
|
|
|
|
|
|
| | Tous types | 100 | 86 | 32 | 106 | 95 | 83 | 24 | 109 | 13 | 3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.14: | Résultats traditionnels quantitatifs comparés de l’utilisation
d’un seuil de rejet des réponses sans concordance syntaxique avec la question
nul ou minimal. |
|
Les variations du seuil de concordance en dessous duquel les réponses
doivent être supprimées peuvent fluctuer. Les résultats avec un seuil
à 0% et à 10% sont identiques, les questions étant généralement trop
brèves pour contenir plus de dix dépendances. Les variations de résultats
commencent à 20%. Le tableau 7.15 page présente les résultats pour
un enrichissement qui comprend l’ensemble des méthodes décrites avec
des seuils de 0%, 10%, 20%, 30% et 40%, attendu que l’examen des
différentes méthodes d’enrichissement n’apporte rien à nos constatations
antérieures .
Le tableau 7.16 page présente les résultats quantifiés correspondants.
|
|
|
|
|
|
|
|
|
|
|
| | Seuil | Précision | Rappel | F-m1 | F-m2 | F-m3 |
|
|
|
|
|
|
|
|
|
|
|
| | 0% | 79.83% | 38.15% | 65.52 | 51.63 | 42.60 |
|
|
|
|
|
| | 10% | 79.83% | 38.15% | 65.52 | 51.63 | 42.60 |
|
|
|
|
|
| | 20% | 79.49% | 37.35% | 64.85 | 50.82 | 41.78 |
|
|
|
|
|
| | 30% | 79.49% | 37.35% | 64.85 | 50.82 | 41.78 |
|
|
|
|
|
| | 40% | 81.31% | 34.94% | 64.25 | 48.88 | 39.44 |
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.15: | Résultats traditionnels des variations du seuil de concordance
pour un enrichissement tous types confondus. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Seuil | Exact | 1 exact | Faux | Sans | Rejet | Rej. exact |
|
|
|
|
|
|
|
|
|
|
|
|
|
| | 0% | 95 | 83 | 24 | 109 | 13 | 3 |
|
|
|
|
|
|
| | 10% | 95 | 83 | 24 | 109 | 13 | 3 |
|
|
|
|
|
|
| | 20% | 93 | 81 | 24 | 111 | 15 | 3 |
|
|
|
|
|
|
| | 30% | 93 | 81 | 24 | 111 | 15 | 3 |
|
|
|
|
|
|
| | 40% | 86 | 76 | 20 | 117 | 24 | 3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.16: | Résultats traditionnels quantitatifs des variations du seuil de
concordance pour un enrichissement tous types confondus. |
|
L’évolution des résultats en fonction du renforcement des contraintes
syntaxiques n’est pas très probant. En effet, l’évolution réelle des résultats
demande un seuil très élevé, en dessous duquel ni la précision, ni le rappel ne
bouge beaucoup. Il faut en effet un seuil de 40% au moins pour voir une
amélioration significative de la précision. Cette amélioration s’effectue au
détriment du rappel, et cette perte du rappel est plus importante que l’apport en
précision, comme le prouve la baisse de la F-mesure qui équilibre l’importance de
la précision et du rappel. La hausse de ce seuil ne permet un gain de précision
qu’au prix d’une perte plus importante du rappel. Le tableau quantitatif permet
d’expliquer la faible variation des résultats avant un seuil de 40% : les réponses
rejetées sont relativement peu nombreuses avant cette limite de 40%, et surtout
leur nombre ne varie pas beaucoup. Mais dès le seuil de 40%, la contrainte
syntaxique est plus efficace et l’élimination de réponses, même de bonnes
réponses ,
est plus importante.
Il nous reste maintenant à analyser les résultats produits par la variation du
dernier paramètre que nous pouvons modifier, c’est-à-dire le focus. Dès lors que
l’unité lexicale désignée par le focus n’est pas requise dans les réponses, les
propositions sont beaucoup plus nombreuses du fait de l’élargissement des
contraintes.
Les tableaux 7.17 page et 7.18 page comparent les résultats obtenus
sans l’exigence de la présence du focus en faisant varier de nulle (aucun
seuil de rejet) à faible (rejet des propositions avec 0% de concordance)
la contrainte du seuil de concordance des dépendances entre question
et réponses. Ces résultats très peu contraints obtiennent un taux de
rappel spécialement élevé, au détriment de la précision. La F-mesure
privilégiant la précision (β=0.5) est basse même si les autres scores sont
honorables.
Les résultats quantitatifs indiquent par ailleurs que les réponses erronées sont
très nombreuses. L’ajout d’une contrainte avec un seuil de concordance à 0%
n’améliore que faiblement les performances du système. Comme nous l’avons
constaté précédemment, les contraintes basses sur les réponses peu concordantes,
lorsque le système ne limite pas les propositions à un petit nombre, n’ont que
peu d’impact sur les résultats. Un seuil de concordance de 10% permet d’ailleurs
d’obtenir des résultats identiques à ceux atteints lorsque le seuil est de
0%.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | | Sans seuil | Avec seuil à 0%
| | Enrichissement | Précision | Rappel | F-m1 | F-m2 | F-m3 | Précision | Rappel | F-m1 | F-m2 | F-m3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Syntaxe | 31.63% | 42.17% | 33.29 | 36.14 | 39.53 | 32.89% | 40.16% | 34.13 | 36.17 | 38.46 |
|
|
|
|
|
|
|
|
|
|
| | Synonymes | 30.41% | 44.58% | 32.48 | 36.16 | 40.78 | 31.33% | 41.77% | 32.97 | 35.80 | 39.16 |
|
|
|
|
|
|
|
|
|
|
| | D | 31.51% | 46.18% | 33.65 | 37.46 | 42.25 | 32.63% | 43.37% | 34.33 | 37.24 | 40.69 |
|
|
|
|
|
|
|
|
|
|
| | D-Syn | 30.34% | 46.18% | 32.58 | 36.62 | 41.82 | 31.40% | 43.37% | 33.23 | 36.42 | 40.30 |
|
|
|
|
|
|
|
|
|
|
| | D-B | 31.45% | 46.99% | 33.68 | 37.68 | 42.76 | 32.64% | 44.18% | 34.44 | 37.54 | 41.26 |
|
|
|
|
|
|
|
|
|
|
| | D-EWN-M | 32.35% | 48.19% | 34.62 | 38.71 | 43.89 | 33.53% | 45.38% | 35.38 | 38.57 | 42.39 |
|
|
|
|
|
|
|
|
|
|
| | D-Dér | 31.28% | 46.99% | 33.52 | 37.56 | 42.70 | 32.45% | 44.18% | 34.27 | 37.41 | 41.20 |
|
|
|
|
|
|
|
|
|
|
| | D-B-EWN-M-Dér | 32.04% | 49.80% | 34.50 | 38.99 | 44.83 | 33.33% | 46.99% | 35.39 | 39.00 | 43.43 |
|
|
|
|
|
|
|
|
|
|
| | Tous types | 31.00% | 49.80% | 33.53 | 38.21 | 44.41 | 32.23% | 46.99% | 34.39 | 38.24 | 43.05 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.17: | Résultats traditionnels comparés de l’utilisation ou non d’un
seuil de concordance sans la présence du lexème focus. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | | Sans coréférence | Avec coréférence
| | Enrichissement | Exact | 1 exact | Faux | Sans | Exact | 1 exact | Faux | Sans | Rejet | Rej. exact |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Syntaxe | 105 | 82 | 227 | 110 | 100 | 79 | 204 | 113 | 28 | 8 |
|
|
|
|
|
|
|
|
|
|
| | Synonymes | 111 | 86 | 254 | 106 | 104 | 82 | 228 | 110 | 33 | 9 |
|
|
|
|
|
|
|
|
|
|
| | D | 115 | 90 | 250 | 102 | 108 | 86 | 223 | 106 | 34 | 10 |
|
|
|
|
|
|
|
|
|
|
| | D-Syn | 115 | 90 | 264 | 102 | 108 | 86 | 236 | 106 | 35 | 10 |
|
|
|
|
|
|
|
|
|
|
| | D-B | 117 | 91 | 255 | 100 | 110 | 87 | 227 | 104 | 35 | 10 |
|
|
|
|
|
|
|
|
|
|
| | D-EWN-M | 120 | 95 | 251 | 97 | 113 | 91 | 224 | 101 | 34 | 10 |
|
|
|
|
|
|
|
|
|
|
| | D-Dér | 117 | 91 | 257 | 101 | 110 | 87 | 229 | 105 | 35 | 10 |
|
|
|
|
|
|
|
|
|
|
| | D-B-EWN-M-Dér | 124 | 97 | 263 | 93 | 117 | 93 | 234 | 97 | 36 | 1 |
|
|
|
|
|
|
|
|
|
|
| | Tous types | 124 | 97 | 276 | 93 | 117 | 93 | 246 | 97 | 37 | 10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.18: | Résultats traditionnels quantitatifs comparés de l’utilisation ou
non d’un seuil de concordance sans la présence du lexème focus. |
|
Les résultats obtenus en appliquant des seuils plus élevés permettent d’obtenir
un compromis acceptable entre les différentes mesures. Le graphique 7.4 page
précédente qui présente les courbes quantitatives à chaque seuil testé permet
d’évaluer visuellement l’impact des rejets sur les résultats. En effet, un seuil de
20% permet de retrouver un niveau de précision intéressant tout en conservant
un rappel élevé étant donné que le nombre de propositions éliminées augmente
très significativement. La F-mesure équilibrée (β=1) permet même de
constater que c’est le meilleur compromis testé pour ce système. Les
tableaux 7.19 page et 7.20 page contiennent les résultats comparés de
l’interrogation de la base documentaire sans utilisation du focus dans la
réponse et à des seuils de concordance inexistant et à 0%, 10%, 20%, 30%
et 40%. Seuls les résultats de tous les enrichissements confondus sont
indiqués, le détail des différents enrichissements n’appelant pas de nouvelle
constatation.
|
|
|
|
|
|
|
|
|
|
|
| | Seuil | Précision | Rappel | F-m1 | F-m2 | F-m3 |
|
|
|
|
|
|
|
|
|
|
|
| | Sans seuil | 31.00% | 49.80% | 33.53 | 38.21 | 44.41 |
|
|
|
|
|
| | 0% | 32.23% | 46.99% | 34.39 | 38.24 | 43.05 |
|
|
|
|
|
| | 10% | 32.32% | 46.99% | 34.47 | 38.30 | 43.08 |
|
|
|
|
|
| | 20% | 78.29% | 40.56% | 66.01 | 53.44 | 44.89 |
|
|
|
|
|
| | 30% | 80.00% | 38.55% | 65.84 | 52.03 | 43.01 |
|
|
|
|
|
| | 40% | 81.82% | 36.14% | 65.31 | 50.14 | 40.69 |
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.19: | Résultats traditionnels comparés des variations du seuil de
concordance sans la présence du lexème focus. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Seuil | Exact | 1 exact | Faux | Sans | Rejet | Rej. exact |
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Sans seuil | 124 | 97 | 276 | 93 | — | — |
|
|
|
|
|
|
| | 0% | 117 | 93 | 246 | 97 | 37 | 10 |
|
|
|
|
|
|
| | 10% | 117 | 93 | 245 | 98 | 38 | 10 |
|
|
|
|
|
|
| | 20% | 101 | 87 | 28 | 105 | 271 | 24 |
|
|
|
|
|
|
| | 30% | 96 | 84 | 24 | 108 | 280 | 26 |
|
|
|
|
|
|
| | 40% | 90 | 79 | 20 | 114 | 290 | 26 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.20: | Résultats traditionnels quantitatifs comparés des variations du
seuil de concordance sans la présence du lexème focus. |
|
Ces tableaux confirment que le pic des résultats est bien atteint au seuil de
20%. Au-delà, la précision augmente tandis que le rappel diminue, suite au
renforcement des contraintes. En deçà de 20%, les contraintes ne sont plus
suffisantes pour garantir une précision acceptable, même au regard du rappel
important. Les indications quantitatives indiquent que le nombre des réponses
rejetées ne devient significatif qu’à partir d’un seuil de 20%, au regard du nombre
d’erreurs proposées. La figure 7.5 page montre bien l’influence bénéfique des
contraintes de seuil sur la précision à partir de 20% lorsque le focus n’est pas
exploité.
La fenêtre de réponse disponible dans le cadre d’autres applications de gestion de
l’information que la tâche de question-réponse ne correspond pas forcément à
une phrase. Notre méthode permet d’interroger également une base textuelle à
d’autres niveaux, tant du document lui-même que du paragraphe, pour autant
que cette notion soit définie au préalable.
Toutefois, nous ne disposons pas actuellement des mêmes fonctionnalités
pour manipuler l’information dans ces fenêtres. En effet, nous ne pouvons pas
traiter séparément les dépendances extraites lors de l’analyse de la base
textuelle. De ce fait, il ne nous est pas possible d’établir un seuil de rejet des
réponses dont le schéma syntaxique ne correspond pas suffisamment à la
question. Par contre, nous pouvons gérer l’utilisation du lexème désigné par
le focus ainsi que le module de résolution de coréférence des pronoms
sujets.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | | Sans coréférence | Avec coréférence
| | Enrichissement | Précision | Rappel | F-m1 | F-m2 | F-m3 | Précision | Rappel | F-m1 | F-m2 | F-m3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Plancher | 83.02% | 35.34% | 65.38 | 49.58 | 39.93 | — | — | — | — | — |
|
|
|
|
|
|
|
|
|
|
| | Syn. aveugles | 77.87% | 38.15% | 64.45 | 51.21 | 42.49 | — | — | — | — | — |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Syntaxe | 83.84% | 33.33% | 64.34 | 47.70 | 37.90 | 82.05% | 38.55% | 66.95 | 52.46 | 43.13 |
|
|
|
|
|
|
|
|
|
|
| | Synonymes | 78.07% | 35.74% | 63.12 | 49.04 | 40.09 | 77.44% | 41.37% | 65.94 | 53.93 | 45.62 |
|
|
|
|
|
|
|
|
|
|
| | D | 74.02% | 37.75% | 62.09 | 50.00 | 41.85 | 75.69% | 43.78% | 66.06 | 55.47 | 47.81 |
|
|
|
|
|
|
|
|
|
|
| | D-Syn | 73.44% | 37.75% | 61.76 | 49.87 | 41.81 | 75.17% | 43.78% | 65.74 | 55.33 | 47.77 |
|
|
|
|
|
|
|
|
|
|
| | D-B | 69.34% | 38.15% | 59.60 | 49.22 | 41.92 | 70.97% | 44.18% | 63.29 | 54.46 | 47.78 |
|
|
|
|
|
|
|
|
|
|
| | D-EWN-M | 72.86% | 40.96% | 63.04 | 52.44 | 44.89 | 74.68% | 47.39% | 66.97 | 57.99 | 51.13 |
|
|
|
|
|
|
|
|
|
|
| | D-Dér | 73.64% | 38.15% | 62.09 | 50.26 | 42.22 | 75.34% | 44.18% | 66.03 | 55.70 | 48.16 |
|
|
|
|
|
|
|
|
|
|
| | D-B-EWN-M-Dér | 68.87% | 41.77% | 60.96 | 52.00 | 45.34 | 71.01% | 48.19% | 64.86 | 57.42 | 51.50 |
|
|
|
|
|
|
|
|
|
|
| | Tous | 68.87% | 41.77% | 60.96 | 52.00 | 45.34 | 70.59% | 48.19% | 64.59 | 57.28 | 51.46 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.21: | Résultats traditionnels avec et sans utilisation de la coréférence
pour une réponse d’un paragraphe. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | | Sans coréférence | Avec coréférence
| | Enrichissement | Exact | 1 exact | Faux | Sans | Exact | 1 exact | Faux | Sans |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Plancher | 102 | 88 | 23 | 104 | — | — | — | — |
|
|
|
|
|
|
|
|
| | Syn. aveugles | 110 | 94 | 32 | 97 | — | — | — | — |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Syntaxe | 83 | 74 | 16 | 121 | 96 | 85 | 21 | 107 |
|
|
|
|
|
|
|
|
| | Synonymes | 89 | 78 | 25 | 115 | 103 | 90 | 30 | 101 |
|
|
|
|
|
|
|
|
| | D | 94 | 83 | 33 | 109 | 109 | 95 | 35 | 95 |
|
|
|
|
|
|
|
|
| | D-Syn | 94 | 83 | 34 | 108 | 109 | 95 | 36 | 95 |
|
|
|
|
|
|
|
|
| | D-B | 95 | 84 | 42 | 105 | 110 | 96 | 45 | 92 |
|
|
|
|
|
|
|
|
| | D-EWN-M | 102 | 89 | 38 | 100 | 118 | 102 | 40 | 86 |
|
|
|
|
|
|
|
|
| | D-Dér | 95 | 84 | 34 | 108 | 110 | 96 | 36 | 94 |
|
|
|
|
|
|
|
|
| | D-B-EWN-M-Dér | 104 | 91 | 47 | 96 | 120 | 104 | 49 | 83 |
|
|
|
|
|
|
|
|
| | Tous | 104 | 91 | 47 | 97 | 120 | 104 | 50 | 84 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.22: | Résultats traditionnels quantitatifs comparés de l’utilisation
d’un seuil de rejet des réponses sans concordance syntaxique avec la question
nul ou minimal. |
|
Les tableaux 7.21 page et 7.22 page précédente montrent les résultats
comparés de l’interrogation de la base textuelle au niveau du paragraphe avec
d’un côté l’utilisation du module de résolution de la coréférence et de l’autre
la désactivation de ce même module. Par ailleurs, les tableaux 7.23
page et 7.24 page comparent les résultats obtenus pour l’ensemble des
enrichissements confondus lorsque la présence du lexème focus est exigé dans la
réponse et lorsqu’il ne l’est pas.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | | Focus requis | Focus non requis
| | Enrichissement | Précision | Rappel | F-m1 | F-m2 | F-m3 | Précision | Rappel | F-m1 | F-m2 | F-m3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Plancher | 83.02% | 35.34% | 65.38 | 49.58 | 39.93 | — | — | — | — | — |
|
|
|
|
|
|
|
|
|
|
| | Syn. aveugles | 77.87% | 38.15% | 64.45 | 51.21 | 42.49 | — | — | — | — | — |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Avec coréférence | 70.59% | 48.19% | 64.59 | 57.28 | 51.46 | 35.86% | 57.03% | 38.73 | 44.03 | 51.01 |
|
|
|
|
|
|
|
|
|
|
| | Sans coréférence | 68.87% | 41.77% | 60.96 | 52.00 | 45.34 | 33.97% | 50.20% | 36.32 | 40.52 | 45.82 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.23: | Résultats traditionnels de l’interrogation de la base au niveau
paragraphe : variation des paramètres. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | | Focus requis | Focus non requis
| | | Exact | 1 exact | Faux | Sans | Exact | 1 exact | Faux | Sans |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Plancher | 88 | 77 | 18 | 118 | — | — | —- | —- |
|
|
|
|
|
|
|
|
| | Syn. aveugles | 95 | 82 | 27 | 111 | — | — | — | — |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Avec coréférence | 120 | 104 | 50 | 84 | 142 | 116 | 254 | 73 |
|
|
|
|
|
|
|
|
| | Sans coréférence | 104 | 91 | 47 | 97 | 125 | 102 | 243 | 83 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.24: | Résultats traditionnels quantitatifs de l’interrogation de la base
au niveau paragraphe : variation des paramètres. |
|
Les résultats obtenus montrent une nouvelle fois la qualité de l’enrichissement
issu de la synonymie contextuelle, et principalement des dictionnaires
sémantiques. C’est en effet leur information qui permet d’atteindre le rappel le
plus large tout en maintenant la précision à un degré élevé, quel que soit le
paramètre modifié. Par ailleurs, l’enrichissement synonymique aveugle des
lexèmes non désambiguïsés confirme la pauvreté de son apport, négatif dans
tous les cas à ce niveau. Pour la première fois, l’enrichissement issu de la
dérivation morphologique génère des erreurs en nombre plus important que des
réponses correctes.
Par ailleurs, si l’importance du focus reste déterminante pour la précision,
l’utilisation du module de résolution de coréférence est moins déterminante que
lors de son utilisation dans des phrases. En effet, l’entité désignée par le pronom
anaphorique est souvent présente dans le même paragraphe que ce pronom.
L’utilisation de ce module est donc moins déterminante à ce niveau de
réponse. Le rappel reste toutefois bien plus important lorsque ce module est
exploité.
L’interrogation de la base documentaire au niveau textuel permet de
confirmer nos observations sur les différentes méthodes d’enrichissement,
notamment sur l’importance des synonymes contextuels, surtout s’ils proviennent
d’un dictionnaire sémantique. Par ailleurs, l’importance de la présence du focus
s’amenuise à mesure que la fenêtre de réponse est plus large car la faiblesse de la
précision, qui toutefois s’est améliorée, est contrebalancée par le rappel élevé.
L’importance du module de coréférence a maintenant complètement disparu,
car l’antécédent anaphorique est toujours présent dans le document.
Les résultats comparés de cette interrogation au niveau du document
sont présentés dans les tableaux 7.25 page et 7.26 page . Comme
les résultats de l’interrogation de la base textuelle avec utilisation de
la technique de résolution de la coréférence sont identiques à ceux qui
n’exploitent pas cette fonctionnalité, ces tableaux ne distinguent pas son
exploitation.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | | Focus requis | Focus non requis
| | Enrichissement | Précision | Rappel | F-m1 | F-m2 | F-m3 | Précision | Rappel | F-m1 | F-m2 | F-m3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Plancher | 82.88% | 36.95% | 66.38 | 51.11 | 41.55 | — | — | — | — | — |
|
|
|
|
|
|
|
|
|
|
| | Syn. aveugles | 78.86% | 38.96% | 65.45 | 52.15 | 43.34 | — | — | — | — | — |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Syntaxe | 81.61% | 28.51% | 59.46 | 42.26 | 32.78 | 66.67% | 32.13% | 54.87 | 43.36 | 35.84 |
|
|
|
|
|
|
|
|
|
|
| | Synonymes | 77.78% | 30.92% | 59.69 | 44.25 | 35.16 | 65.91% | 34.94% | 55.98 | 45.67 | 38.56 |
|
|
|
|
|
|
|
|
|
|
| | D | 73.64% | 32.53% | 58.78 | 45.13 | 36.62 | 63.64% | 36.55% | 55.42 | 46.43 | 39.95 |
|
|
|
|
|
|
|
|
|
|
| | D-Syn | 70.18% | 32.13% | 56.74 | 44.08 | 36.04 | 61.22% | 36.14% | 53.76 | 45.45 | 39.37 |
|
|
|
|
|
|
|
|
|
|
| | D-B | 68.70% | 31.73% | 55.71 | 43.41 | 35.55 | 60.14% | 35.74% | 52.91 | 44.84 | 38.90 |
|
|
|
|
|
|
|
|
|
|
| | D-EWN-M | 75.21% | 36.55% | 62.07 | 49.19 | 40.73 | 65.58% | 40.56% | 58.38 | 50.12 | 43.91 |
|
|
|
|
|
|
|
|
|
|
| | D-Dér | 73.21% | 32.93% | 58.82 | 45.43 | 37.00 | 63.45% | 36.95% | 55.49 | 46.70 | 40.32 |
|
|
|
|
|
|
|
|
|
|
| | D-B-EWN-M-Dér | 72.22% | 36.55% | 60.42 | 48.53 | 40.55 | 63.52% | 40.56% | 57.06 | 49.51 | 43.72 |
|
|
|
|
|
|
|
|
|
|
| | Tous | 72.22% | 36.55% | 60.42 | 48.53 | 40.55 | 63.52% | 40.56% | 57.06 | 49.51 | 43.72 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.25: | Résultats traditionnels de l’interrogation de la base au niveau
texte : variation des paramètres. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | | Focus requis | Focus non requis
| | Enrichissement | Exact | 1 exact | Faux | Sans | Exact | 1 exact | Faux | Sans |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | Plancher | 92 | 92 | 19 | 89 | — | — | — | — |
|
|
|
|
|
|
|
|
| | Syn. aveugles | 97 | 97 | 26 | 77 | — | — | — | — |
|
|
|
|
|
|
|
|
| | Syntaxe | 71 | 71 | 16 | 113 | 80 | 80 | 40 | 80 |
|
|
|
|
|
|
|
|
| | Synonymes | 77 | 77 | 22 | 101 | 87 | 87 | 45 | 68 |
|
|
|
|
|
|
|
|
| | D | 81 | 81 | 29 | 90 | 91 | 91 | 52 | 57 |
|
|
|
|
|
|
|
|
| | D-Syn | 80 | 80 | 34 | 86 | 90 | 90 | 57 | 53 |
|
|
|
|
|
|
|
|
| | D-B | 79 | 79 | 36 | 85 | 89 | 89 | 59 | 52 |
|
|
|
|
|
|
|
|
| | D-EWN-M | 91 | 91 | 30 | 79 | 101 | 101 | 53 | 46 |
|
|
|
|
|
|
|
|
| | D-Dér | 82 | 82 | 30 | 88 | 92 | 92 | 53 | 55 |
|
|
|
|
|
|
|
|
| | D-B-EWN-M-Dér | 91 | 91 | 35 | 74 | 101 | 101 | 58 | 41 |
|
|
|
|
|
|
|
|
| | Tous | 91 | 91 | 35 | 74 | 101 | 101 | 58 | 41 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| | |
| Tab. 7.26: | Résultats traditionnels quantitatifs de l’interrogation de la base
au niveau texte : variation des paramètres. |
|