|
Une application qui entend gérer le sens du texte dans une base documentaire à travers l’analyse linguistique des énoncés qui la composent ne peut se passer d’une procédure visant à identifier la signification des unités de sens manipulées dans les documents de cette base. La désambiguïsation sémantique (Word Sense Disambiguation, WSD), qui permet de décider du sens des unités lexicales dans un texte, constitue une « tâche intermédiaire »[Wilks et Stevenson, 1996] essentielle dans le cadre de nombreux processus de traitement automatique de la langue 13, et principalement dans les applications visant la compréhension de texte en langage naturel [Ide et Véronis, 1998].
Du fait de cette grande variété d’intérêts, les difficultés liées à la problématique de la désambiguïsation sémantique ont très tôt été identifiées. Toutefois, les solutions qui ont été proposées dans chaque domaine ont également été multiples et très diverses, en fonction des besoins et des savoirs afférents à chacune des matières concernées. La définition du problème elle-même ne fait pas l’unanimité. En effet, si un consensus est atteint pour définir la désambiguïsation sémantique comme l’association d’un mot apparaissant dans un contexte avec sa signification ou sa définition – laquelle peut être distinguée des autres définitions qu’on peut attribuer à ce mot –, en revanche le même accord n’existe pas pour ses sous-tâches.
Il s’agit en effet de déterminer d’abord l’ensemble des sens que peut prendre chaque mot dans la langue. [Kelly et Stone, 1975] montre que l’attribution objective d’un sens particulier à une unité lexicale polysémique dans un contexte donné n’est pas chose aisée. Toutefois, à l’heure actuelle, les travaux en désambiguïsation sémantique s’effectuent principalement à partir de sens prédéfinis, grâce à diverses ressources lexicales et sémantiques. D’autre part, l’assignation d’un sens particulier à une unité lexicale exploite deux informations principales, à savoir le contexte d’apparition des occurrences de chaque mot, et une ou plusieurs bases de connaissances externes qui permettent de mettre en rapport les mots en contexte avec leur sens. C’est sur la nature de la base de connaissance que survient ici le désaccord, certaines méthodes privilégiant des ressources d’un ordre plutôt lexical pour fournir ces données (knowledge-driven word sense disambiguation), d’autres leur préférant des informations sur le contexte provenant de corpus aux unités lexicales préalablement désambiguïsées (corpus-based word sense disambiguation).
Parmi les différentes méthodes de détermination de la signification des mots en contexte, nous ne nous intéressons toutefois qu’à celles qui correspondent aux restrictions que nous nous sommes fixées dans le cadre de cette thèse, à savoir les méthodes qui se fondent sur des critères linguistiques pour effectuer la tâche qui leur est confiée. Par ailleurs, la désambiguïsation sémantique s’inscrit ici dans le contexte d’un processus d’enrichissement du texte qui lui est soumis, et doit de ce fait permettre la sélection de l’information lexico-syntaxique la plus riche et la plus précise, ce qui implique l’utilisation d’une ressource lexicale bien structurée. De plus, le texte qui est soumis à la désambiguïsation sémantique est libre et susceptible d’atteindre un volume important, d’où une nécessité de robustesse. Ces exigences limitent donc l’horizon des systèmes de désambiguïsation sémantique auxquels nous nous intéressons. Nous ne ferons qu’évoquer succinctement les autres.
Dans les années qui ont suivi la seconde guerre mondiale, la traduction automatique fut la première spécialité à s’intéresser aux problèmes liés à la polysémie des mots. Très vite, les travaux qui s’y consacrèrent admirent l’importance déterminante du contexte d’un mot à désambiguïser (que nous appelons « cible », target) [Weaver, 1949, Kaplan, 1955], et ensuite l’influence très marquée des relations syntaxiques entre la cible et son contexte [Reifler, 1955].
Par la suite, les besoins de connaissance d’un univers plus large pour effectuer les distinctions de sens ont initié deux tendances : tout d’abord la réduction du traitement à des domaines restreints, ce qui amène l’utilisation d’un lexique spécialisé dont la polysémie est limitée et donc la désambiguïsation facilitée [Panov, 1960], mais cette approche n’est pas envisageable dans le cadre du texte tout-venant ; ensuite, inspirée par la notion de langue-pivot, l’idée développée par [Masterman, 1957, Masterman, 1961] d’une abstraction de la forme de surface en concepts dans un réseau sémantique structuré, qui permet de choisir le sens correspondant au concept le plus proche du contexte. Cette seconde tendance très novatrice préfigure le travail de l’intelligence artificielle en désambiguïsation sémantique. Par ailleurs, la direction prise entre autres par les approches décrites dans [Pimsleur, 1957] et dans [Madhu et Lytle, 1965], qui exploitent l’étude quantitative de la polysémie du lexique ainsi que la probabilité d’apparition d’un sens dans un contexte donné pour effectuer le choix du sens, inaugure l’application de méthodes statistiques au domaine.
La plupart des méthodes de sélection du sens en intelligence artificielle n’ont donné lieu qu’à des implémentations extrêmement limitées au niveau du vocabulaire et au niveau du contexte. Cette limitation ne permet pas d’appliquer ces méthodes à du texte réel. Toutefois, certaines approches sont intéressantes par leur principe, qui pourra être réutilisé dans d’autres perspectives. Le réseau sémantique de [Masterman, 1961] permet d’abstraire le sens des phrases dans une langue-pivot composée de concepts fondamentaux. Autour d’une centaine de types de concepts primitifs (thing, do...), un dictionnaire de 15 000 concepts est construit sous la forme d’un réseau hiérarchique qui autorise l’héritage vertical descendant des propriétés. Le choix des sens est implicite et s’effectue au niveau de la phrase : ce sont les nœuds du réseau correspondant aux concepts les plus proches qui sont activés, fournissant ainsi la signification de chacune des unités lexicales. Les approches symboliques ultérieures qui visent l’exploitation d’un réseau sémantique vont s’atteler à donner une étiquette sémantique aux liens qui constituent le réseau [Quillian, 1968], ainsi qu’à fournir un cadre informationnel sur les unités lexicales et leurs relations entre elles [Hayes, 1977], mais conservent le principe du chemin le plus court entre deux nœuds comme meilleur choix de sens.
Le système proposé dans [Hirst, 1987] exploite lui aussi un réseau sémantique et des cadres informationnels liés aux unités lexicales afin de définir le chemin le plus court entre deux nœuds, mais il introduit en plus un mécanisme appelé « mots polaroïds » (polaroid words) qui élimine progressivement les sens qui ne peuvent être appliqués à cause d’indices fournis soit par une analyse syntaxique, soit par l’information présente dans le cadre informationnel. Il note toutefois que si la phrase sort du cadre informationnel défini, aucune décision ne pourra être prise.
Tout en abandonnant le principe du réseau sémantique, [Wilks, 1975] insiste lui aussi sur les relations que la cible entretient avec son entourage contextuel. Pour chaque unité lexicale, il établit un réseau de préférences sémantiques sous la forme de restrictions de sélection régissant la combinaison syntaxique et sémantique de la cible avec d’autres lexèmes. Ces restrictions peuvent progressivement être assouplies dans les cas où les règles les plus strictes n’aboutissent pas à un résultat.
Pour la désambiguïsation sémantique de sa méthode de compréhension du langage naturel, [Dahlgren, 1988] utilise plusieurs informations, dont des syntagmes figés, des restrictions de sélection syntaxico-sémantiques et un moteur de raisonnement « de bon sens », qui consiste à chercher un ancêtre commun à deux mots appartenant au contexte dans une ontologie, comme [Resnik, 1995] le fera également. Dahlgren note que la moitié des désambiguïsations sont effectuées par ce module ontologique, que les restrictions de sélection des verbes sont une importante source d’information pour la désambiguïsation des noms. Suite à la notion d’« amorçage sémantique » 14 (semantic priming), le courant connexionniste va exploiter les réseaux sémantiques selon des modèles de « propagation d’activation » (spreading activation), c’est-à-dire que dans un réseau sémantique, les concepts sont activés lorsqu’ils sont mentionnés dans le document, et cette activation est transmise aux nœuds qui sont connectés à ces concepts. L’activation se délite progressivement, mais il est possible qu’un même nœud soit activé par différentes sources, ce qui renforce son activation par rapport aux autres. Bien que ces approches pondérées ne correspondent pas à une méthode linguistique, [Bookman, 1987] a introduit dans le réseau des traits sémantiques (opposition fondamentales, durée, lieux...) pour permettre de contraindre plus précisément la sémantique des nœuds activés. Ces approches n’ont cependant pas été menées à une échelle suffisante pour être exploitables dans une application en taille réelle.
Les méthodes de désambiguïsation sémantique avancées dans le domaine de l’intelligence artificielle présentent surtout le défaut d’une couverture lexicale insuffisante. Dès que les possibilités matérielles ont permis la gestion de grands volumes de données, les recherches en désambiguïsation sémantique se sont attachées à utiliser des ressources lexicales de grandes dimensions. [Michiels, 1982] attire notamment l’attention sur la richesse de l’information contenue dans ces ressources. Il insiste sur l’intérêt que ces données représentent pour le traitement du langage en général, et pour le traitement de la sémantique en particulier.
Les premières tentatives ont été faites avec les dictionnaires au format électronique, dont on essayait d’extraire une information lexicale et sémantique. Cependant, une information rigoureuse n’est pas facile à obtenir, ces dictionnaires présentant deux défauts majeurs : ils comportent de grandes incohérences [Kilgarriff, 1994] et ils sont conçus pour être utilisés par des humains, sans tenir compte des besoins logiciels. Dès lors, les approches appliquent un principe de sécurité, préférant donc la robustesse à la finesse. L’idée force de ce principe est qu’un mot polysémique voisin d’un autre mot dans un contexte possède celui de ses sens qui se rapproche le plus du sens de son voisin. Les indices de proximité entre les sens de deux mots varient en fonction des méthodes. Ce principe favorise bien entendu les modèles statistiques, même si des notions plus linguistiques peuvent y être adjointes dans certaines approches.
[Lesk, 1996] imagine un système qui génère une base de connaissances à partir d’un dictionnaire de langue, constituant pour chaque sens de chaque lexème une « signature » composée de la liste des mots apparaissant dans la définition de ce sens. La désambiguïsation de la cible se fait par sélection du sens qui présente la plus grande intersection avec les signatures des mots du contexte. [Wilks et al., 1993] améliore cette méthode fruste en augmentant la part accordée aux statistiques : il calcule la fréquence de co-occurrence des mots dans les définitions afin de définir un degré de relation entre les mots. [Véronis et Ide, 1990] reprend aussi la méthode de Lesk et l’exploite dans un réseau neuronal où chaque mot est relié à ses sens, qui sont reliés à chaque mot de leur définition, eux-même reliés à chacun de leurs sens, etc.
[Cowie et al., 1992] s’intéresse à une information supplémentaire, à savoir les catégories sémantiques définies dans le Longman Dictionary of Contemporary English (LDOCE) qui sont de deux types : les box codes qui présentent des catégories sémantiques (abstrait, humain...) et les subject codes qui correspondent à des domaines d’application (économie, ingénierie...). Ils améliorent la méthode de Lesk en imposant au sens sélectionné une correspondance de trait sémantique avec son contexte. Il reste que cette information sémantique n’est pas systématique dans le LDOCE. Plus grave, le LDOCE, comme la plupart des dictionnaires électroniques, manque cruellement d’informations pragmatiques permettant d’établir des liens entre les unités lexicales et entre les informations dont elles sont porteuses.
Les thesaurus sont le deuxième type de ressources lexicales, plus systématiques que les dictionnaires et fournissant des relations essentiellement synonymiques entre les mots. Chaque occurrence d’un mot dans une catégorie d’un thesaurus correspond à un de ses sens, chaque catégorie rassemblant des mots ayant approximativement le même sens. Cette particularité de conception a valu aux thesaurus d’être très tôt exploités pour le traitement automatique de la sémantique, notamment pour la constitution du réseau sémantique de [Masterman, 1957] (voir 2.3.1 page §).
Les méthodes qui exploitent les thesaurus sont généralement axées sur une information statistique importante, à l’image de [Yarowsky, 1992], qui établit un modèle statistique basé sur le contexte. Chaque catégorie du Roget’s Thesaurus est considérée comme une classe de mots. À partir de chacun des éléments de chaque classe, Yarowsky construit un ensemble contextuel de cent mots extraits d’un corpus et établit la probabilité statistique que chaque mot de la classe et chacun des cent mots de son contexte soient co-occurrents. La désambiguïsation sémantique est effectuée par l’application de la formule de Bayes sur la probabilité pour chaque classe contenant la cible d’être choisie.
Enfin, les dictionnaires informatiques, exploitables seulement par une application logicielle, rassemblent sous la forme de bases de connaissances des informations plus ou moins liées au lexique 15 au niveau morphologique, syntaxique et/ou sémantique. La désambiguïsation sémantique exploite essentiellement WordNet [Fellbaum, 1998b], dont l’information peut se rapprocher tantôt d’un dictionnaire (définitions), tantôt d’un thesaurus (groupes de mots quasi-synonymes appelés synsets, hiérarchie conceptuelle), ou bien d’un réseau sémantique (relations hyponymiques, méronymiques, antonymiques), etc. On notera toutefois que cette ressource ne contient pas d’information syntaxique.
[Voorhees, 1993] exploite l’information hyponymique de WordNet dans une perspective de recherche d’information en cherchant, grâce à la construction des sous-graphes hyponymiques de chaque mot, à établir des similitudes sémantiques entre les mots de la requête et ceux de sa réponse. Ces similitudes sont obtenues grâce au décompte des synsets des unités composant la requête et ceux des documents. Cependant, aucun choix réel de sens fin n’est effectué par cette méthode, seulement un rapprochement de deux mots. [Sussna, 1993], dans une semblable perspective de recherche d’information, attribue un poids à chaque type de relation entre deux unités lexicales et donne à chaque lexème une mesure liée au nombre de relations de même type qui la relient à d’autres. Ces mesures servent de base à un calcul appliqué aux chemins qui relient deux unités lexicales voisines dans un texte, et le sens choisi est celui qui obtient le meilleur résultat. Sussna observe l’importance de sens proches dans un même contexte. Il note également l’intérêt d’utiliser d’autres relations sémantiques que le classique is-a. S’appuyant sur les travaux décrits dans [Dahlgren, 1988] en intelligence artificielle, [Resnik, 1995] recherche dans la hiérarchie is-a un terme générique commun à deux lexèmes (ou plus) d’un texte et calcule la longueur du chemin permettant de déterminer la portion d’information commune aux lexèmes. Toutefois, il se distingue de [Sussna, 1993] en considérant que la distance entre deux nœuds du réseau varie selon le type de relation qui les unit.
Nous notons que ces différentes méthodes ne s’appliquent qu’aux substantifs, et que la distinction entre les sens est effectuée par le calcul d’une distance ou d’un poids pour chaque sens de chaque mot, qui permettent de rapprocher ou d’opposer des données sémantiques. Il est toutefois intéressant de constater le bénéfice apporté d’une part par les différentes relations sémantiques qui constituent le réseau, et d’autre part par la distinction de l’importance qu’il faut apporter à ces relations sémantiques. Cependant, le contenu de WordNet n’est pas parfait, la distinction des sens elle-même étant souvent trop fine 16, et l’information syntaxique manquant cruellement.
Un autre type de ressources lexicales informatiques existe, qui ne décrit pas les différents sens des mots de manière énumérative, mais sous la forme de règles qui exposent les sens de manière relative. C’est le lexique génératif [Pustejovsky, 1991]. Divers travaux tentent d’utiliser des ressources génératives pour effectuer un travail de désambiguïsation sémantique [Viegas et Bouillon, 1994, Viegas et al., 1999]. Toutefois, l’absence de dictionnaire génératif pour le français et le manque d’information permettant l’enrichissement de texte nous ont amené à écarter ces méthodes.
Les méthodes basées sur l’étude de grands corpus textuels s’adaptent bien à l’élaboration de modèles statistiques qui reposent sur l’étude de fréquences rencontrées dans les textes. Cependant, des méthodes linguistiques basées sur des observations et sur la construction de règles à partir de ces observations ont abondamment utilisé les corpus pour obtenir l’information dont elles avaient besoin. [Weiss, 1973] a démontré sur cinq mots et un corpus d’une vingtaine de phrases pour chaque mot que des règles de désambiguïsation sémantique pouvaient être extraites de phrases étiquetées sémantiquement. [Kelly et Stone, 1975] a suivi son exemple : à partir d’un corpus de 500 000 mots, ils ont extrait manuellement des règles de désambiguïsation sémantique pour chaque sens de l 800 mots polysémiques. Ces règles exploitaient des indices tels que la collocation, les relations syntaxiques et l’appartenance à une même catégorie sémantique. Bien que réalisés sur une petite échelle, ces tests ont donné d’excellents résultats.
Cependant, les modèles statistiques se sont rapidement imposés lorsque le volume de données contenues dans les corpus a commencé à devenir réellement important : [Black, 1988], par exemple, a extrait des arbres de décision sémantique d’un corpus de 22 millions de mots dont il avait étiqueté environ 2 000 occurrences de cinq lexèmes. Toutefois, cette méthode elle-même, comme celles de Kelly et Stone, met en évidence les difficultés d’exploiter des corpus pour un traitement sémantique. En effet, il s’agit non seulement d’étiqueter manuellement ces textes, mais aussi d’obtenir des documents qui comportent des occurrences de chacun des sens de chacun des mots du lexique, et cela en nombre suffisant pour pouvoir inférer des normes de comportement, que ce soit dans les méthodes linguistiques ou statistiques. Les tentatives d’améliorations ont donc porté sur deux problèmes.
Il a d’abord fallu trouver des moyens d’étiqueter par le sens ces grandes bases textuelles par des techniques automatiques. Une solution proposée est l’amorçage (bootstrapping), qui comporte une phase d’apprentissage d’informations qui permettront ultérieurement un étiquetage sémantique automatique. La technique de l’amorçage est toutefois généralement soumise à des données quantitatives, que ce soit la méthode de [Hearst, 1991], qui propose d’extraire des données statistiques du contexte des dix à trente premières occurrences – manuellement étiquetées – de chaque mot dans le corpus, ou celle de [Schütze, 1992], basée sur des tétragrammes et sur la représentation vectorielle du sens de l’ensemble des mots formant le contexte de la cible.
Une autre méthode a été testée pour éviter l’étiquetage manuel des corpus : l’utilisation de corpus bilingues alignés, qui permettent de distinguer les différents sens d’un mot par leur différentes traductions [Gale et al., 1993, Dagan et al., 1991]. Cependant, les sens possédant une même traduction ne peuvent être distingués. De plus, les corpus bilingues alignés correspondent le plus souvent à un domaine et à un registre de langue particuliers, et ne se révèlent pas forcément très représentatifs de la langue.
L’autre obstacle qu’il a fallu franchir concerne le manque de données représentatives de l’ensemble des sens de l’ensemble des mots du lexique. Le lissage (smoothing) est une méthode utilisée pour éviter que la probabilité d’apparition d’un sens rare et non représenté dans le corpus soit égale à zéro. Elle s’appuie sur des fréquences de co-occurrences et à ce titre ne retient pas notre attention. Les modèles basés sur des classes de mots (class-based models) s’appuient sur l’hypothèse que des unités lexicales appartenant à une même classe de mots peuvent être utilisés indifféremment. Ce type d’approche est tenté à partir de classes de mots appartenant à la taxinomie de WordNet [Resnik, 1992]. Aux catégories du Roget’s Thesaurus [Roget et Dutch, 1972, Yarowsky, 1992] ou aux codes du LDOCE [Slator, 1992, Liddy et Paik, 1992]. Cependant, cette hypothèse trop stricte est à l’origine de la perte de toute information qui n’est pas partagée par l’ensemble des membres de la classe. Un autre modèle s’est donc développé, basé sur les similarités (similarity-based methods), qui part du même postulat, mais ne construit pas de classes fixes, chacun des lexèmes appartenant potentiellement à plusieurs ensembles de mots similaires [Dagan et al., 1993].
Au cours de cet examen des approches utilisées pour gérer le problème de l’ambiguïté sémantique lexicale, nous avons fait plusieurs observations qui doivent nous servir pour le choix d’une méthodologie applicable à nos besoins. Tout d’abord, il a été remarqué très tôt que l’étude du contexte de la cible constituait la principale information qui permet d’en sélectionner le sens adéquat. Par la suite, on a constaté l’importance prépondérante des éléments du contexte syntaxiquement liés à la cible pour effectuer ce choix.
Par ailleurs, nous voulons utiliser une méthode de désambiguïsation sémantique dans une perspective d’enrichissement et d’expansion de texte, c’est-à-dire que le choix d’un sens correct doit également permettre la sélection d’une information qui s’y rattache. Il s’agit donc d’utiliser une ressource lexicale descriptive qui comporte un maximum de données morphologiques, syntaxiques et bien entendu sémantiques. Seul un dictionnaire électronique est actuellement capable de fournir ce type d’information, les ressources de type WordNet ne présentant aucune information syntaxique qui permettrait de gérer le contexte syntaxique de la cible. Toutefois, il n’est pas question de rejeter certaines utilisations des données sémantiques que contiennent cette catégorie de ressources, et notamment les relations qu’elles sont capables de décrire entre les mots.
Enfin, l’importance des informations linguistiques contenues dans les corpus étiquetés n’est pas négligeable, comme l’ont montré [Weiss, 1973, Kelly et Stone, 1975]. L’exploitation de tels corpus, pour peu qu’ils existent, ne doit en aucun cas être délaissée.
Pour ces différentes raisons, nous avons décidé de nous pencher particulièrement sur la méthodologie de désambiguïsation sémantique développée à XRCE. Cette méthode, simple à l’origine, exploitait à ses débuts une matrice HMM dans une fenêtre contextuelle de un mot avant et après la cible [Segond et al., 1997]. Une collaboration avec le CELI [Dini et al., 1998] a permis une amélioration du système grâce à l’utilisation de l’algorithme d’apprentissage de Brill, et l’extension de la fenêtre contextuelle aux unités lexicales reliées syntaxiquement à la cible. Enfin, la maturité qui nous intéresse a été atteinte [Segond et al., 1998] : le système actuel présente l’avantage d’exploiter l’information contextuelle lexicale et syntaxique, qui utilise un dictionnaire électronique constitué de manière à éviter les incohérence habituelles de ses homologues et présentant de nombreux exemples répartis par sens, exploitables comme un corpus étiqueté. Enfin, cette méthode utilise dans la création de ses règles l’information taxinomique de WordNet pour l’anglais, celle d’AlethDic pour le français afin d’apporter aux règles de désambiguïsation lexicales l’information sémantique qui leur manque et mettre les lexèmes en relation les uns avec les autres.
La méthode déjà expérimentée au CELI et à XRCE consiste à effectuer une analyse linguistique – essentiellement lexicale et syntaxique – de l’environnement typique d’un mot polysémique dans chacun de ses sens pour constituer un ensemble de règles de discrimination de ces sens. On comprendra dès lors que l’efficacité de cette méthode est liée à la qualité des informations contextuelles présentes dans le dictionnaire, ce qui justifie l’attention avec laquelle le choix de cette ressource est réalisé.
La méthode que nous décrivons ici a d’abord été implémentée et validée dans le cadre des compétitions Senseval [Dini et al., 2000] et Romanseval [Segond et al., 2000] (cf. section 2.3.4 page §) puis perfectionnée suite aux résultats obtenus par [Brun, 2000]. Les outils d’analyses en sont IFSP (Incremental Finite-State Parser) pour l’analyse syntaxique (cf. section 2.2.2 page §) et le Xerox Morphological Analyser, transducteur morpho-lexical contenant l’information morphologique correspondant au lexique encodé pour l’analyse morpho-lexicale. La ressource lexicale utilisée est la version électronique d’un dictionnaire bilingue français-anglais publié conjointement par les éditions Hachette et Oxford University Press [Corréard et Grundy, 1994] 17.
Remarquons certaines caractéristiques de ce module de désambiguïsation sémantique. Tout d’abord, il s’agit d’un système basé sur une ressource lexicale. Le dictionnaire utilisé comme référence est un dictionnaire bilingue, très riche en exemples et en indications contextuelles. Bien que cette particularité soit très utile dans des application multilingues, et notamment l’aide à la traduction, un tel dictionnaire s’applique peu à nos besoins (identification de synonymes et autres relations sémantiques, dérivations, catégorisation...). Il nous faut donc choisir une autre ressource lexicale de référence qui se prète mieux à nos besoins (cf. chapitre 3 page §). Ensuite, l’intégration de ce prototype s’est faite au sein d’une plate-forme développée à XRCE. Cette plate-forme regroupe différents outils d’analyse textuelle sous le nom de XeLDA (Xerox Linguistics Development Architecture). Or les outils et ressources de XeLDA ne présentent ni la souplesse, ni les fonctionnalités, ni toutes les qualités des outils dont nous avons parlé précédemment. Il nous faudra donc nous extraire de cette architecture et présenter une nouvelle application basée sur les principes qui nous intéressent dans cette méthode. Enfin, deux étapes sont nécessaires à cette méthode de désambiguïsation sémantique : l’extraction des règles de désambiguïsation, c’est-à-dire la génération, à partir d’informations issues de l’analyse du dictionnaire, des règles dans un formalisme rigoureux compatible avec le système de désambiguïsation sémantique applicatif, et l’application de ces règles au cours de l’analyse textuelle.
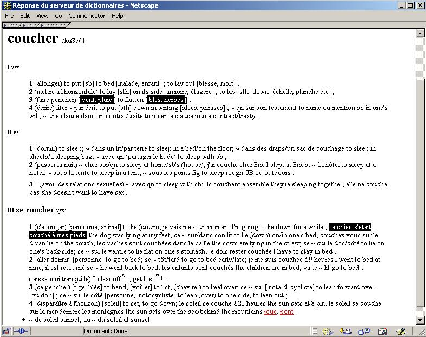
Le principe de la méthode de désambiguïsation qui nous intéresse consiste à analyser les données syntaxico-sémantiques de chaque sens de chaque lemme pour relever les indices permettant d’effectuer une discrimination de sens lorsque ces indices sont détectés dans le contexte de l’unité lexicale à désambiguïser. De la sorte, chaque règle de désambiguïsation est attachée à un seul sens et elle associe ce sens à une information précise considérée comme typique de cette acception du lemme par le dictionnaire. Nous illustrons l’extraction des règles de désambiguïsation sémantiques au travers de l’entrée de coucher dans l’OHFD (cf. figure 2.12 page §).
Un examen des données linguistiques présentes dans le dictionnaire utilisé constitue donc le principe essentiel de la méthode de constitution d’un ensemble de règles lexicales de désambiguïsation. Cet examen, qui peut varier selon la ressource utilisée, se penche sur diverses informations. La base des exemples constitue la principale source de données, comme le montre la phrase Le chien s’était couché à mes pieds (sens III.1 dans notre cas illustratif). En effet, on peut voir que l’analyse de cet exemple permet de dégager certaines relations syntaxiques typiques de cette acception du lemme coucher. On en extrait une règle impliquant cette acception III.1 si dans le contexte du lemme coucher on trouve les mots chien ou pied, chien entretenant avec le lemme coucher une relation de type sujet d’un verbe coucher en construction pronominale (SUBJREFLEX(chien,coucher)) et pied étant le complément prépositionnel modifieur de verbe introduit par la préposition à (VMODOBJ(coucher, à, pied)).
De telles règles peuvent être construites pour chaque sens de chaque entrée du dictionnaire qui comporte un exemple, par simple analyse syntaxique de cet exemple. Chaque dépendance mettant en cause le mot-vedette constitue un élément de la condition d’application de la règle pour le sens dans lequel l’exemple apparaît.
Dans le même ordre d’idée, le dictionnaire OHFD présente régulièrement des indicateurs de collocation pour un sens donné dans une entrée. Une collocation décrit l’association habituelle d’une unité lexicale avec une autre dans un énoncé. Lorsque la collocation du mot-vedette avec un autre lexème est jugée suffisamment discriminante d’une acception par le lexicographe chargé de l’entrée, un indicateur de collocation est utilisé dans le dictionnaire. L’OHFD comporte de plus cette particularité qui veut que la position de l’indicateur de collocation par rapport à la traduction de la vedette soit indicative de la construction syntaxique habituellement entretenue entre ce mot-vedette et sa collocation. Ces informations sont d’une précieuse aide dans la constitution de règles de désambiguïsation sémantique. Notre cas illustratif nous montre que dans le cadre du sens I.3 du lemme coucher, la collocation vent (ou pluie) est un sujet typique tandis que blés (ou herbes) est un objet distinctif de coucher pour ce même sens. On peut donc obtenir deux règles de désambiguïsation impliquant le sens I.3 si le contexte du lemme coucher offre soit le mot vent (ou pluie) comme sujet de coucher (SUBJ(vent,coucher)), soit le mot blés (ou herbes) comme objet de coucher (DOBJ(coucher,blés)). Cette démarche permet d’obtenir les dépendances syntaxiques qui correspondent à l’analyse de phrases générées à partir de ces informations de collocation (cf. exemple 2.14 page §). Toutefois, le fait de rester au niveau syntaxique et de ne pas construire réellement les phrases permet d’éviter les problèmes liés à la génération (flexions et règles orthographiques).
|
Dépendances générées à partir des collocations :
Le vent couche les blés . SUBJ(pluie,coucher)
La pluie couche les herbes .
|
De telles règles sont lexicales, c’est-à-dire qu’elles s’appliquent exclusivement à la désambiguïsation sémantique du lexème pour lequel elles ont été construites.
Le travail que nous avons effectué en désambiguïsation sémantique lexicale nous a d’abord amené à étudier les possibilités d’amélioration de la méthode que nous avons exposée. Ces améliorations se sont faites selon trois perspectives. La première est la recherche de la généralisation des règles afin de sortir du champ restreint du lexique strict et limité des exemples et collocations. En cela, nous avons pris exemple sur le travail effectué par [Brun, 2000] dans la version anglaise du prototype. Là où le vocabulaire était remplacé par une ou plusieurs des classes sémantiques de WordNet18 à l’intérieur des règles, nous avons fait de même à partir des classes taxinomiques de AlethDic19. Si nous reprenons l’exemple de notre cas illustratif (Le chien s’était couché à mes pieds), la règle généralisée correspondante serait : l’acception III.1 du lemme coucher est choisie si dans le contexte de coucher on trouve un mot qui appartient à la classe ANIMAL ou à la classe INSTRUMENT (classes du mot chien) entretenant une relation SUBJREFLEX (sujet d’un verbe pronominal) avec coucher ou un mot de classes FORME, MESURE, MEUBLE, CORPS ou VEGETAL (classes du mot pied) entretenant une relation VMODOBJ (complément prépositionnel modifieur de verbe) avec coucher.
|
Règles lexicales pour l’exemple Le chien s’était couché à mes pieds :
Classes sémantiques :
Règles sémantiques pour l’exemple Le chien s’était couché à mes pieds :
|
La deuxième perspective d’amélioration est centrée sur l’exploitation d’autres informations présentes dans le dictionnaire. Les possibilités de recherche dans cette voie sont bien entendu limitées par deux facteurs, à savoir la variété des types d’informations présentes dans le dictionnaire, et la latitude laissée dans leur exploitation par les outils d’analyse utilisés par le système. Nous avons tenté d’exploiter l’information morpho-syntaxique restrictive fournie par le dictionnaire pour certaines acceptions afin d’imposer ou de filtrer certains sens dans des contextes déterminés. Dans notre cas illustratif, deux circonstances mettent en lumière l’exploitation de ces données morpho-syntaxiques. La première acception principale de l’entrée coucher met en jeu la transitivité de coucher, ce qui permet d’éliminer les interprétations liées à la construction intransitive de coucher (II.1 à II.3) dans les cas où le contexte donne un objet direct à coucher (voir 2.12 page §). De même, la dernière acception principale (III.1 à III.4) se consacre principalement aux acceptions de la construction pronominale de coucher. Dès lors, si le contexte d’apparition de coucher présente une construction pronominale, c’est au sein de ce sens principal que l’acception correcte se trouve et les autres interprétations peuvent être éliminées. Le principe du filtrage de l’application de certaines règles ne peut toutefois pas être inséré dans les règles elles-mêmes car ce formalisme ne permet pas d’utiliser plusieurs arguments conditionnels, encore moins de manipuler des opérateurs booléens. Les informations supplémentaires que nous exploitons doivent donc appartenir à un ensemble fermé relativement restreint pour créer un ensemble de conditions applicables lors de l’application des règles de désambiguïsation sémantique, et non lors de leur création.
|
Énoncé :
Elle s’est couchée au chevet de son compagnon de vie. Dépendance impliquant le verbe coucher : SUBJREFLEX(elle,coucher) VMODOBJ(coucher,à+le,chevet) Classe sémantique de chevet : MEUBLE Règle de désambiguïsation sémantique appliquée :
| ||||||
L’exemple 2.16 page précédente illustre le mode de fonctionnement d’une règle de désambiguïsation sémantique : pour une entrée donnée (coucher), lorsqu’il y a compatibilité entre une dépendance de l’énoncé et celle qui est présente dans une règle (VMODOBJ(coucher,à,MEUBLE)), le numéro de sens correspondant à cette règle (coucher.3.1) est sélectionné. Nous avons ici affaire à une règle sémantique, qui remplace certaines unités lexicales par leur classe sémantique (MEUBLE pour chevet). On peut voir combien ce type de règle permet d’élargir les perspectives d’une règle lexicale. En effet, l’énoncé présent ne présente aucun rapport lexical avec l’exemple utilisé pour créer la règle qui s’est appliquée (cf. exemples 2.13 page § et 2.15 page §).
Une dernière perspective de travail concerne des dépendances syntaxiques que nous appelons transitives. Il s’agit de dépendances dont la définition par l’analyseur syntaxique est multiple, mais qui recouvrent une seule relation syntaxico-sémantique malgré une présentation syntaxique différente (par exemple sujet d’un verbe actif et complément d’agent d’un verbe passif), ou même correspondent à une même relation syntaxique selon la grammaire traditionnelle (par exemple sujet d’un verbe et sujet inverse d’un verbe). Nous avons donc étudié les dépendances syntaxiques extraites par l’analyseur syntaxique pour déterminer celles qui, contenant les mêmes arguments, sont semblables sémantiquement. Les plus représentatives de ces dépendances sont celles qui font intervenir le complément d’agent et le sujet actif, ou l’adjectif attribut et l’épithète, mais de nombreuses autres équivalences sont concernées. En effet, si la présentation phrastique est différente entre chacun des membres de ces couples, le sens des ces groupes n’en reste pas moins le même, et les indices linguistiques permettant une désambiguïsation efficace doivent être relevés. Nous avons donc mis en place une procédure de mise en concordance des différentes relations syntaxiques équivalentes pour générer de nouvelles règles correspondant aux règles de désambiguïsation originelles. Notre cas illustratif nous avait donné une relation de type sujet (voir 2.14 page §) entre vent et coucher. Les relations équivalentes sont INGSUBJ (sujet du verbe au participe ou au gérondif), RELSUBJ (antécédent d’un pronom relatif sujet du verbe), INVSUBJ (sujet inversé du verbe) et PAGENT (complément d’agent du verbe passif).
|
Dépendance originelle :
Règle de désambiguïsation issue de cette dépendance :
Règles générées à partir de dépendances équivalentes :
|
La génération des règles s’effectue automatiquement au travers de XeLDA. Cette opération est effectuée selon la progression lexicale 20. Pour chacune des entrées de l’OHFD, une consultation du dictionnaire (lookup) est effectuée. Chacun des sens est traité séparément et l’information qui lui est propre est analysée pour constituer les règles de désambiguïsation sémantique selon les modalités présentées ci-dessus : analyse syntaxique des exemples et extraction des dépendances ; génération des relations syntaxiques liées aux collocants ; généralisation du lexique en effectuant une consultation sur les classes sémantiques de AlethDic ; création éventuelle de filtres liés à l’information morphologique ; génération des relations syntaxiques équivalentes. Tout cela aboutit à la constitution des règles de désambiguïsation sémantique correspondantes.
Une fois la base de règles de désambiguïsation sémantique constituée, son exploitation est assez simple puisqu’elle est pour ainsi dire symétrique à sa phase de construction. Elle se base en effet sur une analyse du texte à désambiguïser semblable à celle qui a été opérée sur les exemples du dictionnaire. Dès lors, le fonctionnement du module d’application repose sur la plate-forme d’analyse textuelle XeLDA, qui sera chargée d’établir les dépendances syntaxiques entre les mots du textes pour les comparer à celles des règles de désambiguïsation. En cas de déclenchement d’une de ces règles, il appartient également à XeLDA de fournir l’extrait du dictionnaire correspondant à l’acception sélectionnée. C’est là le fonctionnement de base de cette méthode.
|
Lorsque l’herbe d’alpage n’est plus broutée, elle pousse haut
puis elle est couchée par la pluie et les intempéries.
Dépendances impliquant coucher : SUBJPASS(elle,coucher) PAGENT(coucher,par,pluie) Règle de désambiguïsation sémantique originale (cf. figure 2.14 page §) : coucher : SUBJ(pluie,coucher) ==> #coucher.3.1# Règle dérivée appliquée à l’énoncé : coucher : PAGENT(coucher,par,pluie) ==> #coucher.3.1#
|
L’exemple 2.18 page précédente montre l’application d’une règle de désambiguïsation sémantique. La règle qui s’applique est issue d’une information de collocation (cf. exemple 2.14 page §). Elle s’applique pour le verbe coucher et vérifie qu’il entretient une relation PAGENT avec le mot pluie (en tant que relation similaire à une dépendance originale SUBJ(pluie,coucher)). Le numéro de sens est le numéro 3.1 (cf. figure 2.12 page §).
Toutefois, cette simplicité apparente masque une certaine complexité dans le déclenchement des règles. En effet, il n’est pas rare – surtout du fait de la généralisation des règles lexicales à travers les classes sémantiques d’AlethDic – que plusieurs règles soient susceptibles de convenir à un même contexte. Si ces règles conduisent à une seule et même acception, le problème se résout de lui-même, aucune ambiguïté n’étant maintenue. Dans le cas contraire, un processus de discrimination permet de choisir une seule acception, directement ou par l’attribution d’un poids à chacun des sens proposés, selon une méthode que nous allons présenter plus loin.
Tout d’abord, une des qualités qui a suscité le choix de ce dictionnaire réside dans l’ordonnancement statistique des sens de chacune de ses entrées. En effet, l’OHFD a été construit à l’aide de très grands corpus 21, et les lexèmes qui y sont décrits voient leurs sens ordonnés selon leur fréquence dans ces corpus. Un aspect de cette méthode de désambiguïsation sémantique est donc basé sur l’hypothèse que de deux sens envisageables dans un contexte et confirmés chacun par une règle de désambiguïsation, c’est celui qui est le plus fréquent qui est probablement le bon. Cette heuristique ne repose bien entendu sur aucun argument linguistique. De plus, aucun indice contextuel n’est susceptible de faire varier l’interprétation d’un mot en fonction de l’environnement dans lequel il se trouve. Elle ne s’affirmera dès lors que dans les cas où aucune autre tentative de désambiguïsation n’aura fonctionné. D’autres méthodes plus contextuelles sont proposées ci-dessous pour résoudre les cas de désambiguïsations concurrentes22.
Un paramètre est particulièrement valorisé lorsque la désambiguïsation standard n’a pas suffi et que le système se trouve dans un cas de désambiguïsations concurrentes. Il s’agit de la nature de l’information qui est à l’origine de la création de la règle. Une règle lexicale est considérée comme apportant une information sûre, et la distance entre l’information du dictionnaire et le contexte d’application d’une règle qui correspond à ce contexte sera donc nulle (0.0). Une règle lexicale a toujours la prépondérance sur une règle dite sémantique. Toutefois, l’information lexicale est subdivisée en différents types, certains ayant une plus grande importance que d’autres.
La figure 2.19 page § indique l’ordre d’importance décroissant de chacun de ces types d’information. Le premier type d’information est celui qui a été considéré par les lexicographes comme le plus figé et le dernier comme le moins figé.
|
règle issue de collocation
|
Si le niveau d’importance du type d’information à l’origine des règles qui s’appliquent ne permet pas un choix définitif entre règles lexicales, le déclenchement de plusieurs règles lexicales différentes pour un même sens accorde bien sûr à ce sens un poids proportionnel au nombre de règles qui se déclenchent pour ce sens. Enfin, si aucune de ces deux méthode n’a donné de résultat, le choix s’effectuera dès lors selon l’ordonnancement des acceptions interne au dictionnaire.
L’application des règles dites « sémantiques » implique en revanche
une distance d’autant plus importante que le contexte déclencheur est
sémantiquement éloigné de l’ensemble de classes propres à la règle. Afin
d’effectuer la sélection, la distance entre la liste L1 des classes sémantiques d’une
règle potentielle et la liste L2 des classes sémantiques associées à l’argument de
la relation en contexte est calculée comme suit :
d = 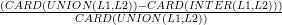
De la sorte, le choix de la règle se fait lorsque la distance est la moins élevée entre le contexte et l’information du dictionnaire. Cette distance peut varier de 0.0 – lorsque toutes les classes proposées par le contexte sont semblables à toutes les classes proposées par la règle – à 1.0 – lorsque aucune des classes n’est commune au contexte et au dictionnaire. Dans le cas où plusieurs règles sémantiques désignent le même sens, les distances calculées pour chacune de ces règles sont multipliées entre elles, ce qui a pour effet de réduire la distance globale pour le sens concerné et donc d’augmenter la probabilité de sélection de ce sens. Il peut aussi arriver que des règles sémantiques de même distance avec le texte soient concurrentes. Dans ce cas, c’est la nature de l’information qui préside au choix de la règle selon les modalités présentés plus haut. Si l’information à l’origine des règles concurrentes est de même nature, c’est dès lors l’ordonnancement des sens du dictionnaire qui décide du choix à appliquer. En effet, les sens de chaque mot polysémique dans l’OHFD sont ordonnés en fonction de la fréquence de leur représentation dans les corpus qui ont servi à élaborer cette ressource.
Enfin, lorsqu’aucune règle de désambiguïsation sémantique ne peut s’appliquer au contexte du cible, le sens proposé par le système sera le premier sens fourni par le dictionnaire, habituellement l’acception la plus générale, et en tout cas le sens le plus fréquent du mot courant dans les corpus utilisés pour l’élaboration du dictionnaire.
On a déjà pu voir dans l’exposé des différentes méthodes de désambiguïsation sémantique que les démarches lexicales avaient notre préférence dans le cadre de notre méthodologie de traitement de l’information textuelle. La méthode imaginée par Frédérique Segond à XRCE et Luca Dini et Vittorio Di Tomaso au CELI présente non seulement les avantages de ses semblables, mais elle possède également certains atouts qui nous ont amené à la préférer aux autres pour réaliser notre système, bien que nous ayons décidé d’y apporter un certain nombre de modifications dont nous parlerons plus loin (cf. section 5.3 page §).
Les principales qualités des systèmes lexicaux résident dans la qualité de l’information que l’on peut obtenir d’un dictionnaire pour identifier les traits typiques du contexte d’un sens. Un dictionnaire est exploitable comme un corpus étiqueté à la main et vérifié humainement, le plus souvent plusieurs fois. De plus, les dictionnaires présentent habituellement une relative cohérence et homogénéité, ce qui est plus difficilement le cas d’un corpus, par exemple, à moins qu’il n’ait été étudié en profondeur. De tels corpus exploitables sémantiquement sont rares et de dimensions limitées. De plus, il est relativement aisé de changer le dictionnaire d’une méthode lexicale pour en choisir un qui soit mieux adapté aux besoins de la tâche à laquelle on destine le désambiguïsateur sémantique. Enfin, un de nos objectifs, en effectuant une désambiguïsation sémantique étant de relier chaque unité lexicale d’un texte à un maximum d’information la concernant, un dictionnaire est la ressource idéale pour permettre l’identification de cette information.
La méthode de XRCE ajoute à ces avantages l’utilisation soutenue de la syntaxe pour effectuer la discrimination des sens, ce qui permet non seulement d’exploiter une information supplémentaire pour effectuer la tâche de désambiguïsation, mais aussi d’établir des schémas syntaxico-sémantiques lors de l’analyse des textes à désambiguïser, et ainsi préparer un terrain optimal pour vérifier ou infirmer notre hypothèse selon laquelle une telle analyse peut apporter une aide notable pour l’identification et la recherche d’une information dans un texte. Nous notons toutefois que les erreurs qui peuvent survenir au cours de l’analyse syntaxique sont susceptibles de générer du bruit dans les résultats de l’analyse ultérieure effectuée sur les documents. Il importe donc d’utiliser des outils d’analyse les plus performants possible afin d’éviter au maximum ce qui pourrait interférer avec les résultats de la méthode.
De même que les conférences MUC et TREC ont répondu à un besoin d’uniformisation des tâches et de l’évaluation des méthodologies proposées en traitement de l’information, Senseval23 cherche dès sa première campagne en 1999 à définir un protocole d’évaluation des différents systèmes de désambiguïsation, partant de la constatation que les conditions dans lesquelles les différents systèmes présentés dans la littérature étaient jusque là trop différentes pour permettre une comparaison impartiale et juste. Senseval se propose donc de déterminer le cadre définissant la tâche de désambiguïsation sémantique et de fournir un protocole d’évaluation commun sous forme de compétition.
La tâche proposée aux différentes méthodes consiste à associer les occurrences de certains lemmes présents dans un corpus avec leurs sens dans un dictionnaire. Pour la première campagne de Senseval, ce sont les ressources Hector qui ont été choisies [Atkins, 1993], composé d’un fragment de 17 Mo du British National Corpus (BNC) dont l’étiquetage a été réalisé par six lexicographes avec un niveau de convergence de 95 %. Bien que le dictionnaire présente trois niveaux de granularité, c’est le niveau le plus fin qui est retenu pour la tâche de désambiguïsation sémantique.
L’évaluation n’est pas menée sur l’ensemble des mots des textes présentés au système lors de cette première campagne : seules 41 unités lexicales sont concernées (15 substantifs, 13 verbes, 8 adjectifs et 5 mots de catégorie indéterminée)
Lors de la première campagne Senseval, une évaluation analogue a été menée sur deux langues romanes, le français et l’italien, ce qui lui a valu le nom de Romanseval24 [Segond, 2000, Calzolari et Corazzari, 2000]. Cette évaluation applique les mêmes principes que son homologue anglophone mais, pour le français, exploite le dictionnaire Larousse et le corpus du projet Arcade25. Les mots à désambiguïser étaient soixante : vingt substantifs, vingt adjectifs, vingt verbes.
La seconde campagne d’évaluation Senseval menée en 2001 s’est éloignée des principes de la première en s’axant sur une désambiguïsation de l’ensemble des mots du texte, et non plus d’une petite partie prédéfinie d’entre eux. De plus, le dictionnaire dont les sens ont été utilisés comme référence à cette évaluation sont ceux de WordNet. Enfin, l’expérience de Romanseval a été délaissée pour le français, Senseval s’étant étendu à d’autres langues (basque, chinois, tchèque, danois, néerlandais, estonien, italien, japonais, coréen, espagnol, suédois). De ce fait, le système francophone n’a pu participer à cette campagne.
Les critères d’évaluation qui ont présidé aux tests sur le système du français dans [Brun et al., 2001] correspondent à ceux de la campagne Senseval-2, excepté en ce qui concerne l’utilisation des sens de WordNet, puisque cette évaluation concernait des textes francophones. Les sens sont ceux du dictionnaire que nous utilisons pour extraire les règles de désambiguïsation sémantique, l’OHFD [Corréard et Grundy, 1994]. Les résultats présentés dans cette évaluation sont encourageants (cf. tableau 2.1 page §).
|
Suite à cette évaluation, différentes conclusions ont été tirées qui sont remarquables pour nous dans la mesure où cette méthodologie nous intéresse pour le traitement du problème qui nous occupe. Tout d’abord, l’ensemble des erreurs ne sont pas redevables aux règles de désambiguïsation sémantique. En effet, dans certains cas, le défaut provient d’un défaut des analyseurs (morphologique et syntaxique) qui sont appliqués en amont de la désambiguïsation. C’est bien entendu le résultat global qui nous intéresse, mais nous avons vu que nous disposions désormais d’analyseurs plus récents et plus performants.
L’examen des résultats du système de désambiguïsation sémantique pour le français accuse un déficit par rapport à la même méthode appliquée à l’anglais (65 % contre 80 %). Ce déficit est spécialement marqué dans l’utilisation des règles sémantiques (50 % contre 70 %), alors que les règles lexicales restent globalement aussi efficaces (90 %). Le défaut provient donc de la ressource utilisée pour effectuer la généralisation sémantique des règles, AlethDic. En effet, de nombreux défauts de cohérence avec le découpage en sens du dictionnaire de référence, l’OHFD, ont été constatés, ainsi que l’existence de classes sémantiques trop générales ou couvrant des concepts trop divers.
Enfin, une dernière constatation était liée au problème de la faible couverture. Elle provient essentiellement d’un besoin d’information (exemple ou collocation) pour chaque sens de chaque entrée pour construire une règle de désambiguïsation. Ce besoin n’est pas toujours comblé. Pour information, moins de 40 % des entrées de l’OHFD possèdent au minimum une règle de désambiguïsation sémantique. L’information contenue dans le dictionnaire et attachée à un sens particulier de chaque lemme est donc capitale.
Ces remarques tiennent bien compte des réalités auxquelles est confrontée une telle méthode de désambiguïsation sémantique. Il nous faut les prendre en considération lors du choix des ressources lexicales qui y sont adaptées.